Defense Expert Rebuttal Can Neutralize Prosecution Fingerprint Evidence
OVERVIEW
While all forensic science disciplines pose some risk of error, the public typically believes that testimony from fingerprint experts is infallible. By employing rebuttal experts who can educate jurors about the risk of errors or provide opposing evidence, courts can counter this tendency. CSAFE funded researchers conducted a survey to study the effect of rebuttal experts on jurors’ perceptions.
Lead Researchers
Gregory Mitchell Brandon L. Garrett
Journal
Applied Cognitive Psychology
Publication Date
4 April 2021
Publication Number
IN 118 IMPL
Goals
1
Determine if a rebuttal expert’s testimony can affect jurors’ beliefs in the reliability of fingerprint evidence.
2
Examine the responses of jurors with different levels of concern about false acquittals versus false convictions.
The Study
1000
Participants completed a survey which included questions regarding their concerns about false convictions or false acquittals.
The participants were then assigned to random mock trial conditions:
Control condition with no fingerprint evidence
Fingerprint expert testimony with no rebuttal
A methodological rebuttal: the expert focuses on the subjective nature of fingerprint analysis as a whole
An “inconclusive” rebuttal: the expert opines their own comparison was inconclusive due to the poor quality of the evidence
An “exclusion” rebuttal: the expert states that their own comparison shows the defendant could not have been the source of the fingerprints
Results
Trial Condition
% Voting for Conviction
Every group that heard fingerprint expert testimony from the prosecution had a higher percentage vote for conviction than the control.
76% voted for conviction after hearing only the prosecution’s expert. The methodological rebuttal brought this down to 58%, while the inconclusive rebuttal had 38% and the exclusion rebuttal only 32% voting to convict.
Trial Error Aversions
Mean Likelihood D Committed Robbery
Only the control group had a greater number of participants more concerned with false convictions than false acquittals.
Those with strong aversions to false acquittals were less likely to side with the rebuttal expert, except in the case of an exclusion rebuttal.
Focus on the future
While exclusion and inconclusive rebuttals provided the best results for the defense, the methodological rebuttal still significantly impacted the jurors’ views on fingerprint evidence.
Traditional cross-examination seems to have mixed results with forensic experts. This implies that a rebuttal testimony can be more effective and reliable, while producing long-term changes in jurors’ attitudes.
While a rebuttal expert’s testimony can be powerful, much of that power depends on the individual jurors’ personal aversions to trial errors. This could be an important consideration for jury selection in the future.
Check out these resources for additional research
on forensic evidence and juries:
In recent years, new expert admissibility standards in most states call for judges to assess the reliability of forensic expert evidence. However, little has been reported on the education and training law schools offer to law students regarding forensic evidence. Researchers funded by CSAFE conducted a survey to find out how many schools offer forensic science courses, and they also examine the state of forensics in legal education as a whole.
Lead Researchers
Brandon L. Garrett Glinda S. Cooper Quinn Beckham
Journal
Duke Law School Public Law & Legal Theory Series No. 2021-22
Publication Date
15 February 2021
Publication Number
IN 117 IMPL
Goals
1
Review the curricula of law schools across the United States.
2
Discover how many schools offer forensic science courses and what level of training they provide.
3
Discuss the survey results and their implications for the legal education system at large.
The Study
The 2009 National Academy of Sciences Report called for higher quality scientific education in law schools, citing the lack of scientific expertise among lawyers and judges as a longstanding gap. The American Bar Association then adopted a resolution calling for greater forensic sciences training among law students.
In late 2019 and Spring 2020, Garrett et al. searched online listings of courses for 192 law schools included on the 2019 News and World Report ranking list. They then sent questionnaires to faculties of these schools and requested syllabi to examine the coverage of forensic science courses the schools offered.
With the data in hand, Garrett et al. could examine the type of forensic science-related coverage at law schools in the United States.
Results
Only 42 different forensic science courses were identified by the survey, and several schools did not offer any of these courses at all.
Across the board, the courses offered were all for upper-level students, and many courses were not offered every year, further limiting students’ access to forensic science training.
Only two of the reported courses mentioned teaching statistics or quantitative methods; the vast majority only covered legal standards for admissibility of expert evidence.
Compounding this lack of access was a low degree of demand. None of the responding faculty reported having large lecture courses; in fact, many reported class sizes of fewer than twenty students.
Focus on the future
The results of this survey suggest that the 2009 NAS Report’s call for higher standards in forensic science education remain highly relevant and that continuing legal education will be particularly useful to addressing these needs.
In addition to specialty courses in forensics, more general courses in quantitative methods, during and after law school, could provide a better understanding of statistics for future and current lawyers and judges.
There is still much work to be done in order to ensure greater scientific literacy in the legal profession. To quote Jim Dwyer, Barry Scheck, and Peter Neufeld, “A fear of science won’t cut it in an age when many pleas of guilty are predicated on the reports of scientific experts. Every public defender’s office should have at least one lawyer who is not afraid of a test tube.”
Using Mixture Models to Examine
Group Differences Among Jurors:
An Illustration Involving the Perceived Strength of Forensic Science Evidence
OVERVIEW
It is critically important for jurors to be able to understand forensic evidence, and just as important to understand how jurors perceive scientific reports. Researchers have devised a novel approach, using statistical mixture models, to identify subpopulations that appear to respond differently to presentations of forensic evidence.
Lead Researchers
Naomi Kaplan-Damary William C. Thompson Rebecca Hofstein Grady Hal S. Stern
Journal
Law, Probability, and Risk
Publication Date
30 January 2021
Publication Number
IN 116 IMPL
Goals
1
Use statistical models to determine if subpopulations exist among samples of mock jurors.
2
Determine if these subpopulations have clear differences in how they perceive forensic evidence.
THE THREE STUDIES
In three different studies, diverse groups of jury-eligible adults evaluated pairs of statements regarding forensic evidence and judged which statements they felt were stronger.
Each study used different forensic evidence types and different presentations of data, e.g., numbers-based “quantitative” statements and more categorical, “qualitative” statements.
The studies measured five participant characteristics: gender, age, numeracy (ability to work with numbers), education level, and forensic knowledge.
Researchers analyzed the participants’ responses, first using an exploratory analysis which hypothesizes differences in subpopulations defined by characteristics such as age. Then they utilized the novel mixture model approach to examine the data.
Definition:
Mixture model approach: a probabilistic model that detects
subpopulations within a study population empirically, i.e., without a priori hypotheses about their characteristics.
Results
Data from the three studies suggest that subpopulations exist and perceive statements differently.
The mixture model approach found subpopulation structures not detected by the hypothesis-driven approach.
One of the three studies found participants withhigher numeracy tended to respond more strongly to statistical statements, while those withlower numeracy preferred more categorical statements.
higher numeracy
lower numeracy
Focus on the future
The existence of group differences in how evidence is perceived suggests that forensic experts need to present their findings in multiple ways. This would better address the full range of potential jurors.
These studies were limited due to relatively small number of participants. A larger study population may allow us to learn more about the nature of population heterogeneity.
In future studies, Kaplan-Damary et al. recommend a greater number of participants and the consideration of a greater number of personal characteristics.
Mock Jurors’ Evaluation
of Firearm Examiner Testimony
OVERVIEW
Traditionally, firearm and toolmark experts have testified that a weapon leaves “unique” marks on bullets and casings permitting a “source identification” conclusion to be made. While scientific organizations have called this sort of categorical assertion into question, jurors still place a great deal of weight on a firearms expert’s testimony.
To examine the weight jurors place on these testimonies, researchers conducted two studies: the first evaluated if using more cautious language influenced jurors’ opinions on expert testimony, and the second measured if cross-examination altered these opinions.
Lead Researchers
Brandon L. Garrett Nicholas Scurich William E. Crozier
Journal
Law & Human Behavior
Publication Date
2020
Publication Number
IN 115 IMPL
Goals
The team tested four hypotheses in these studies:
1
Jurors will accord significant weight to a testimony that declares a categorical “match” between two casings.
2
Jurors’ opinions will not be changed by more cautious language in a firearms expert testimony.
3
Guilty verdicts would only be lowered by using the most cautious language (i.e., “cannot exclude the gun”).
4
Cross-examination would lower guilty verdicts depending on the specific language used.
The Studies
Study 1:
1,420 participants read a synopsis of a criminal case which included the testimony of a firearms expert. The expert gave one of seven specifically worded conclusions, ranging from a “simple match,” to a more cautious “reasonable degree of ballistic certainty,” to “cannot be excluded.”
The participants then decided whether they would convict based on the testimony.
Study 2:
1,260 participants were given the same synopsis, with two important changes:
The expert’s testimony had three possible conclusions (inconclusive, a conclusive match, or a cautious “cannot be excluded”) rather than seven.
Some participants also heard cross-examination of the firearms expert.
The participants again decided whether they would convict the defendant and rated the testimony’s credibility.
Results
Study 1:
Guilty Verdict
Figure 1. Proportion of guilty verdicts with 95% confidence intervals.
Compared to an inconclusive result, finding a “match” tripled the rate of guilty verdicts. Variations to how the “match” is described did not affect verdicts.
The sole exception is when the match was described as “…the defendant’s gun ‘cannot be excluded’ as the source.” Then the rate of guilty verdicts doubled –– instead of tripled –– compared to an inconclusive result.
Study 2:
Cross-Examination
Conclusion
Proportion of Guilty Verdicts
Figure 2. Proportion of guilty verdicts (with 95% confidence intervals) in each experimental condition.
Cross-examination did not help jurors to consistently discount firearms conclusions. This is consistent with prior work showing mixed effects of cross-examination on jury perceptions of strength of evidence.
‘Cannot exclude’ and ‘identification’ conclusions lead to significantly more “guilty” convictions than the “inconclusive” condition.
Focus on the future
While it is unfortunate that using more cautious language does not affect jurors’ decisions, there is no downside to implementing it because it can prevent misleading or overstated conclusions.
Future studies should provide video testimony and discussion to better mimic a real-world trial.
The methods that firearms experts use have not been adequately tested, so jurors cannot accurately judge the strength of the evidence or the expert’s proficiency. This requires further research into the validity and reliability of firearms comparison methods.
A Field Analysis of Case Processing in One Crime Laboratory
OVERVIEW
While research on error rates and identifying areas of bias and influence in forensic examination exists, most of it occurs under controlled conditions. With this in mind, researchers set out to investigate real-world latent print comparison-based casework performed by the Houston Forensic Science Center (HFSC) and to assess the results of their latent print analyses for an entire year.
Lead Researchers
Brett O. Gardner Sharon Kelley Maddisen Neuman
Journal
Forensic Science International
Publication Date
December 2, 2020
Publication Number
IN 114 LP
THE GOALS
1
Analyze the HFSC latent print unit’s 2018 casework and describe examiner conclusions.
2
Explore what factors might have affected the examiners’ decisions.
3
Establish the extent of differences between individual examiner’s conclusions.
The Study
Researchers gathered data from JusticeTrax, HFSC’s laboratory information management system. With this, they looked at 20,494 latent print samples the HFSC team examined in 2018. In total, 17 different examiners submitted reports that year. All examiners were certified by the International Association for Identification and had anywhere from 5 to 36 years of experience in the field.
When provided a latent print for comparison, the examiners first checked if the print had enough usable data to enter into an Automated Fingerprint Identification System (AFIS). If so, the examiners then made one of three conclusions based on AFIS results:
No Association: The print is not a potential match with any known print in the AFIS database
Preliminary AFIS Association (PAA): The print is a potential match with a known print in the AFIS database
Reverse Hit: The print is not a potential match with any known print in the AFIS database, but later matches to newly added record prints
Results
1
44.8% of the prints examined had enough usable data to enter into AFIS.
44.8%
Out of the 11,812 prints entered into AFIS, only 20.7% (2,429 prints) resulted in a PAA
20.7%
2
Examiners were slightly more likely to conclude a print was sufficient to enter into AFIS in cases involving a person offense (a crime committed against a person)
3
The types of AFIS software used produced vastly different results. The county-level AFIS (called MorphoTrak) and the federal-level AFIS (called Next Generation Identification, or NGI), were both nearly five times more likely to result in a PAA than the state-level AFIS (called NEC).
4
Individual examiners had drastically different standards to whether a print had enough usable data to enter into AFIS, and again regarding whether the AFIS results could be considered a PAA. This could differ by nearly twice as much, as one examiner concluded 13.3% of their AFIS results were PAAs, while another had 27.1% PAAs in their results.
FOCUS ON THE FUTURE
The major differences between the county, state and federal-level AFIS software indicates that more research is needed on AFIS databases to increase their reliability across the board.
These results only reflect the work of one crime lab over the course of one year. Future research should be conducted with multiple labs in various locations.
HFSC made significant changes to its workflow in recent years, which may contribute to the disparity in examiner conclusions.
Treatment of Inconclusives
in the AFTE Range
of Conclusions
OVERVIEW
Several studies have estimated the error rates of firearm examiners in recent years, most of which showed very small error rates overall. However, the actual calculation of these error rates, particularly how each study treats inconclusive results, differed significantly between studies. Researchers funded by CSAFE revisited these studies to see how inconclusive results were treated and how these differences impacted their overall error rate calculations.
Lead Researchers
Heike Hofmann Susan Vanderplas Alicia Carriquiry
Journal
Law, Probability and Risk
Publication Date
September 2020
Publication Number
IN 113 FT
THE GOALS
1
Survey various studies that assess the error rates of firearms examinations.
2
Determine the differences in how inconclusives are treated in each study.
3
Identify areas where these studies can be improved.
The Study
Hofmann et al. surveyed the most cited black box studies involving firearm and toolmark analysis. These studies varied in structure, having closed-set or open-set data. They were also conducted in different regions, either in the United States and Canada or in the European Union. The most relevant difference, however, was how each study treated inconclusive results.
All studies used one of three methods to treat inconclusives:
Option 1: Exclude the inconclusive from the error rate.
Option 2: Include the inconclusive as a correct result.
Option 3: Include the inconclusive as an incorrect result.
Key Terms:
Black Box Study: a study that evaluates only the correctness of a participant’s decisions.
Closed-set Study: one in which all known and questioned samples come from the same source.
Open-set Study: one in which the questioned samples may come from outside sources.
Results
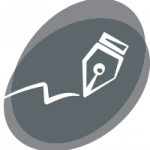
Option 1 was deemed inappropriate for accurate error rates. Option 2 was useful for error rates of the individual examiners, while Option 3 reflected the error rates of the process itself.
Examiners tended to lean towards identification over inconclusive or elimination. In addition, they were far more likely to reach an inconclusive with different-source evidence, which should have been an elimination in nearly all cases.
Process errors occurred at higher rates than examiner errors.
Design issues created a bias toward the prosecution, such as closed-set studies where all samples came from the same source, prescreened kit components which inflated the rate of identifications, or multiple known sources which could not quantify a proper error rate for eliminations.
Fig. 1. Sketch of the relationship between ground truth of evidence (dots) and examiners’ decisions (shaded areas). In a perfect scenario dots only appear on the shaded area of the same colour. Any dots on differently coloured backgrounds indicate an error in the examination process.
FOCUS ON THE FUTURE
Hofmann et al. propose a fourth option:
Include the inconclusive as an elimination.
Calculate the error rates for the examiner and the process separately.
While most studies included a bias toward the prosecution, this was not the case for studies conducted in the European Union. Further study is recommended to verify this difference and determine its cause.
Probabilistic Reporting in
Criminal Cases in the United States:
A Baseline Study
OVERVIEW
Forensic examiners are frequently asked to give reports and testimonies in court and there have been calls for them to report their findings probabilistically. Terms like match, consistent with or identical are categorical in nature, not statistical –– they do not communicate the value of the evidence in terms of probability. While there is robust debate over how forensic scientists should report, less attention is paid to how they do report.
Lead Researchers
Simon A. Cole Matt Barno
Journal
Science & Justice
Publication Date
September 2020
Publication Number
IN 112 IMPL
Key Research Questions
1
To what extent are forensic reports in these disciplines consistent with published standards?
2
To what extent are forensic reports in these disciplines probabilistic, and, if so, how is probability expressed?
APPROACH AND METHODOLOGY
Data Set
572 transcripts and reports from Westlaw, consultants’ files and proficiency tests using a heterogeneous, opportunistic data collection approach.
What
Researchers reviewed reports across four pattern disciplines:
Friction Ridge Prints
Firearms & Toolmarks
Questioned Documents
Shoeprints
How
Using disciplinary standards as a framework, researchers determined the type of report being reviewed and if it used standard terminology. Then, they coded each report both for whether or not it was probabilistic and for the type of language used, such as “same source,” “identified” and “consistent.”
KEY TAKEAWAYS for Practitioners
Across all four disciplines, the prevailing standards for reporting were categorical in nature. The majority of reports analyzed adhered to the reporting standards for their discipline –– but discussion of probability was extremely rare and, even in those cases, frequently used to dismiss the use of probability itself.
reports used categorical terms
in their reporting
reports used terms that adhered
to their disciplinary standards
reports used probabilistic terms
friction ridge prints
89%
firearms & toolmarks
67%
questioned documents
50%
shoemark
87%
friction ridge prints
74%
firearms & toolmarks
100%
questioned documents
96%
shoemark
82%
friction ridge prints
11%
firearms & toolmarks
33%
questioned documents
50%
shoemark
13%
Focus on the future
To increase the probabilistic reporting of forensics results:
1
Incorporate probabilistic reporting into disciplinary standards.
2
Educate practitioners, lawyers, and judges on the reasons for, and importance, of probabilistic reporting.
3
Demand that experts quantify their uncertainty when testifying in court.
Researchers conducted two studies to determine how much an examiner’s blind proficiency score affects the jurors’ confidence in their testimonies.
Lead Researchers
William E. Crozier Jeff Kukucka Brandon L. Garrett
Journal
Forensic Science International
Publication Date
October 2020
Publication Number
IN 111 IMPL
Key Research Questions
1
Determine how disclosing blind proficiency test results can inform a jury’s decision making.
2
Assess how using these proficiency test results in cross-examination can influence jurors.
APPROACH AND METHODOLOGY
WHO
Two separate groups (1,398 participants in Study 1, and 1,420 in Study 2) read a mock trial transcript in which a forensic examiner provided the central evidence.
What
Evidence: bitemark on a victim’s arm or a fingerprint on the robber’s gun.
Blind Proficiency Scores: the examiner either made zero mistakes in the past year (high proficiency), made six mistakes in the past year (low proficiency), claimed high proficiency without proof (high unproven proficiency), or did not discuss their proficiency at all (control).
How
Participants in both studies were asked to render a verdict, estimate the likelihood of the defendant’s guilt, and provide opinions on the examiner and the evidence.
KEY TAKEAWAYS for Practitioners
1
Stating proficiency scores did influence the participants’ verdicts. In both studies, the examiner presented as having low proficiency elicited fewer convictions than the other examiners.
2
While the high-proficiency examiner did not elicit more convictions than the control in Study 1, they not only got more convictions in Study 2, but also proved to withstand cross-examination better than the other examiners.
3
In both studies, proficiency information influenced the participants’ opinions of the examiners themselves, but not their domain’s methods or evidence.
Focus on the future
Despite having lower conviction rates, the low-proficiency examiners were still viewed very favorably and still achieved convictions a majority of the time in both studies (65% and 71% respectively), so fears of an examiner being “burned” by a low-proficiency score are largely overblown.
For defense lawyers to ask about proficiency results, they require access to the information. However, crime laboratories can potentially gain a significant advantage by only disclosing high-proficiency scores. Thus, it is important that such information be disclosed evenly and transparently.
Implementing Blind Proficiency
Testing in Forensic Laboratories:
Motivation, Obstacles, and Recommendations
OVERVIEW
Accredited forensic laboratories are required to conduct proficiency testing –– but most rely solely on declared proficiency tests. A 2014 study showed that only 10% of forensic labs in the United States performed blind proficiency testing, whereas blind tests are standard in other fields including medical and drug testing laboratories. Researchers wanted to identify the barriers to widespread blind proficiency testing and generate solutions to removing these obstacles. After reviewing the existing research, they realized they must convene a meeting of experts to establish an understanding of the challenges to implementation.
Lead Researchers
Robin Mejia Maria Cuellar Jeff Salyards
Journal
Forensic Science International: Synergy
Publication Date
September 2020
Publication Number
IN 110 LP
Participants
CSAFE met with laboratory directors and quality managers from seven forensic laboratory systems in the eastern US and the Houston Forensic Science Center. Two of the quality managers represented the Association of Forensic Quality Assurance Managers (AFQAM). In addition, several professors, graduate students and researchers from three universities attended the meeting.
APPROACH AND METHODOLOGY
1
Compare blind proficiency testing to declared testing then have participants discuss the potential advantages of establishing blind testing as standard.
2
Facilitate and document a discussion of the logistical and cultural barriers labs might face when adopting blind testing. Use this to create a list of challenges.
3
Collect and analyze suggested steps labs can take to overcome the list of challenges to implementing blind proficiency testing.
Challenges and Solutions
Challenge
Proposed Solution
Realistic test case creation
can be complex.
Quality managers develop the expertise to
create test cases; laboratories create a shared
evidence bank.
The development of realistic
submission materials may
be difficult.
The QA staff must develop the knowledge locally
to ensure the test evidence conforms with a
jurisdiction’s typical cases.
Cost may be prohibitively
expensive.
Multiple laboratories can share resources and make joint
purchases; external test providers could develop materials
to lower the cost.
Test must be submitted to
the lab by an outside LEA.
Choosing which law enforcement agency (LEA) to work with
should be decided locally based on the relationship between
lab management and the LEA.
Not all LIMS are equipped
to easily flag and track test
cases.
Labs can choose to either use a Laboratory Information
Management System (LIMS) with this functionality or
develop an in-house system to flag test cases.
Labs must ensure results are
not released as real cases.
The QA team will need to work with individuals in other units
of the lab to prevent accidental releases. It may also be useful
to have contacts in the submitting LEA or local District
Attorney’s office.
Proficiency tests could
impact metrics, so labs
need to decide whether
to include them.
These decisions must be made on a lab-by-lab basis; a
consortium of labs or organizations such as AFQAM can
aid in standardization.
Blind testing challenges
the cultural myth of 100%
accuracy.
Senior lab management must champion blind testing and
show that adding it as a tool will demonstrate both the quality
of examiners and help labs discover and remedy errors.
A Clustering Method for Graphical
Handwriting Components and
Statistical Writership Analysis
OVERVIEW
Researchers developed and tested a statistical algorithm for analyzing the shapes made in handwriting to determine their source. Unlike other programs that analyze what words are written, this algorithm analyzes how the words are written.
Lead Researchers
Amy M. Crawford Nicholas S. Berry Alicia L. Carriquiry
Journal
Statistical Analysis and Data Mining
Publication Date
August 2020
Publication Number
IN 109 HW
The Goals
1
Develop a semi-automated process to examine and compare handwriting samples from questioned and reference documents.
2
Improve upon the existing methodology for determining writership.
APPROACH AND METHODOLOGY
In this study, researchers scanned and analyzed 162 handwritten documents by 27 writers from the Computer Vision Lab database, a publicly available source of handwritten text samples, and broke down the writing into 52,541 unique graphs using the processing program handwriter. From there, a K-means algorithm clustered the graphs into 40 groups of similar graphs, each anchored by a mean or center graph. To allocate graphs to groups, researchers developed a new way to measure the distance between graphs.
Then, researchers processed an additional document from each of the 27 writers –– held back as a “questioned document” –– to test if the algorithm could accurately determine which document belonged to which writer. The new method for clustering graphs appears to be an improvement over the current approach based on adjacency grouping, which relies only on edge connectivity of graphs.
using adjacent clustering
above 50% probability of a match on 23 documents
using dynamic K-means clustering
above 90% probability of a match on 23 documents
correctly matched 26 documents
Key Definitions
Graphs
Simple structures with nodes and edges to represent shapes that constitute handwriting
Writership
The set of graphs a person typically makes when writing
K-means Algorithm
An iterative algorithm that separates data points into clusters based on nearest mean values
KEY TAKEAWAYS FOR PRACTITIONERS
1
The new approach shows promise, as it allows practitioners to more objectively analyze handwriting by studying the way letters and words are formed.
2
When compared to the more readily available but more volatile adjacency grouping method, the K-means clustering method contributed to greater accuracy when trying to identify the writer of a questioned document from among a closed set of potential writers.
FOCUS ON THE FUTURE
The new method favors certain properties of handwriting over others to assess similarities and can be extended to incorporate additional features.
The mean of a group of graphs is often a shape that does not actually occur in the document. Instead of centering groups using a mean graph, researchers are exploring whether using an exemplar graph as a group’s anchor will simplify calculations.
Next Steps
Handwriter
Explore and try the handwriter algorithm by downloading it