CSAFE invites researchers, collaborators, and members of the broader forensics and statistics communities to participate in our Spring 2022 Webinar Series on Friday, April 22, 2022, from 11:00am-Noon CST. The presentation will be “Shining a Light on Black Box Studies.”
Presenters: Dr. Kori Khan Assistant Professor – Iowa State University Dr. Alicia Carriquiry Director – CSAFE
Presentation Description: The American criminal justice system heavily relies on conclusions reached by the forensic science community. In the last ten years, there has been an increased interest in assessing the validity of the methods used to reach such conclusions. For pattern comparison disciplines, however, this can be difficult because the methods employed rely on visual examinations and subjective determinations. Recently, “black box studies” have been put forward as the gold standard for estimating the rate of errors a discipline makes to assist judges in assessing the validity and admissibility of the analysis of forensic evidence. These studies have since been conducted for various disciplines and their findings are used by judges across the country to justify the admission of forensic evidence testimony. These black box studies suffer from flawed experimental designs and inappropriate statistical analyses. We show that these limitations likely underestimate error rates and preclude researchers from making conclusions about a discipline’s error rates. With a view to future studies, we propose minimal statistical criteria for black box studies and describe some of the data that need to be available to plan and implement such studies.
The webinars are free and open to the public, but researchers, collaborators and members of the broader forensics and statistics communities are encouraged to attend. Each 60-minute webinar will allow for discussion and questions.
Sign up on the form below (Chrome & Safari web browsers work the best):
CSAFE invites researchers, collaborators, and members of the broader forensics and statistics communities to participate in our Spring 2022 Webinar Series on Thursday, March 24, 2022, from 11:00am-Noon CST. The presentation will be “Modeling And iNventory of Tread Impression System (MANTIS): The development, deployment and application of an active footwear data collection system.”
Presenters: Dr. Richard Stone Associate Professor – Iowa State University Dr. Susan VanderPlas Assistant Professor – University of Nebraska-Lincoln
Presentation Description: This session will detail the development, capabilities and successful deployment of the Modeling And iNventory of Tread Impression System (MANTIS). MANTIS Optics Scanner takes real time video of gait as the shoe comes in contact with the cover place (again the clear portion). It synchronizes a series of video cameras to create a detailed image of the shoe that can later be processed by software such as Sift + Ransac to create the tread pattern for comparison. The cameras capture between 8 to 15 megapixels for the configuration below (four cameras located in the housing). The use of video optics is expandable to utilize the laser scanning option, though the current utilization focuses on optical capture, thus allowing for tread capture during dynamic movement, i.e. a person walking or running across the system.
The webinars are free and open to the public, but researchers, collaborators and members of the broader forensics and statistics communities are encouraged to attend. Each 60-minute webinar will allow for discussion and questions.
Sign up on the form below (Chrome & Safari web browsers work the best):
CSAFE invites researchers, collaborators, and members of the broader forensics and statistics communities to participate in our Spring 2022 Webinar Series on Thursday, December 9th, 2021, from 9:00-10:00 am CT. The presentation will be “Using Mixture Models to Examine Group Differences: An Illustration Involving the Perceived Strength of Forensic Science Evidence.”
Presenter: Naomi Kaplan Damary, PhD Lecturer – The Hebrew University of Jerusalem
Presentation Description: Forensic examiners compare items to assess whether they originate from a common source. In reaching conclusions, they consider the probability of the observed similarities and differences under alternative assumptions regarding the source(s) of the items (i.e., same or different source). These conclusions can be reported in various ways including likelihood ratios or random match probabilities. Thompson et. al., 2018 examined how lay people perceive the strength of these reports through the use of paired comparison models, obtaining rank-ordered lists of the various statements and an indication of the perceived differences among them. The current study expands this research by examining whether the population is comprised of sub-populations that interpret these statements differently and whether their differences can be characterized. A mixture model that allows for multiple sub-populations with possibly different rankings of the statements is fit to the data and the possibility that covariates explain sub-population membership is considered. A deeper understanding of the way potential jurors perceive various forms of forensic reporting could improve communication in the courtroom.
The webinars are free and open to the public, but researchers, collaborators and members of the broader forensics and statistics communities are encouraged to attend. Each 60-minute webinar will allow for discussion and questions.
CSAFE invites researchers, collaborators, and members of the broader forensics and statistics communities to participate in our Fall 2021 Webinar Series on Thursday, October 14th, 2021, from 11:00am-Noon CDT. The presentation will be “Bloodstain Pattern Analysis Black Box Study.”
Presenters: Austin Hicklin Noblis Forensic Science Group, Director
Paul Kish Forensic Consultant, Paul Erwin Kish Forensic Consultant and Associates
Kevin Winer Director, Kansas City Police Crime Laboratory
Presentation Description: This study was conducted to assess the accuracy and reproducibility of BPA conclusions. Although the analysis of bloodstain pattern evidence left at crime scenes relies on the expert opinions of bloodstain pattern analysts, the accuracy and reproducibility of these conclusions have never been rigorously evaluated at a large scale. We investigated conclusions made by 75 practicing bloodstain pattern analysts on 192 bloodstain patterns selected to be broadly representative of operational casework, resulting in 33,005 responses to prompts and 1,760 short text responses. Our results show that conclusions were often erroneous and often contradicted other analysts. On samples with known causes, 11.2% of responses were erroneous. The results show limited reproducibility of conclusions: 7.8% of responses contradicted other analysts. The disagreements with respect to the meaning and usage of BPA terminology and classifications suggest a need for improved standards. Both semantic differences and contradictory interpretations contributed to errors and disagreements, which could have serious implications if they occurred in casework. Paul Kish, Kevin Winer, and Noblis conducted the study under a grant from the U.S. National Institute of Justice (NIJ).
The webinars are free and open to the public, but researchers, collaborators and members of the broader forensics and statistics communities are encouraged to attend. Each 60-minute webinar will allow for discussion and questions.
Sign up on the form below (Chrome & Safari web browsers work the best):
CSAFE invites researchers, collaborators, and members of the broader forensics and statistics communities to participate in our Spring 2022 Webinar Series on Thursday, February 17th, 2022, from Noon-1:00 pm CST. The presentation will be “Improving Forensic Decision Making: a Human-Cognitive Perspective.”
Presenter: Itiel Dror Cognitive Neuroscience Researcher – University College London
Presentation Description: Humans play a critical role in forensic decision making. Drawing upon classic cognitive and psychological research on factors that influence and underpin expert decision making, this webinar will show the weaknesses and vulnerabilities in forensic decision making. The presenter will also propose a broad and versatile approach to strengthening forensic expert decisions.
The webinars are free and open to the public, but researchers, collaborators and members of the broader forensics and statistics communities are encouraged to attend. Each 60-minute webinar will allow for discussion and questions.
Sign up on the form below (Chrome & Safari web browsers work the best):
This event took place on September 22, 2021. A recording of the event can be found below.
Presenter: Simon Cole Professor – University of California, Irvine
Presentation Description: Over the past decade, with increasing scientific scrutiny on forensic reporting practices, there have been several efforts to introduce statistical thinking and probabilistic reasoning into forensic practice. These efforts have been met with mixed reactions—a common one being skepticism, or downright hostility, towards this objective. For probabilistic reasoning to be adopted in forensic practice, more than statistical knowledge will be necessary. Social scientific knowledge will be critical to effectively understand the sources of concern and barriers to implementation. This study reports the findings of a survey of forensic fingerprint examiners about reporting practices across the discipline and practitioners’ attitudes and characterizations of probabilistic reporting. Overall, despite its adoption by a small number of practitioners, community-wide adoption of probabilistic reporting in the friction ridge discipline faces challenges. We found that almost no respondents currently report probabilistically. Perhaps more surprisingly, most respondents who claimed to report probabilistically, in fact, do not. Furthermore, we found that two-thirds of respondents perceive probabilistic reporting as ‘inappropriate’—their most common concern being that defense attorneys would take advantage of uncertainty or that probabilistic reports would mislead, or be misunderstood by, other criminal justice system actors. If probabilistic reporting is to be adopted, much work is still needed to better educate practitioners on the importance and utility of probabilistic reasoning in order to facilitate a path towards improved reporting practices.
CSAFE invites researchers, collaborators, and members of the broader forensics and statistics communities to participate in our Spring 2021 Webinar Series on Tuesday, May 25th, 2021, from 12:00-1:00pm CST. The presentation will be “Algorithms in Forensic Science: Challenges, Considerations, and a Path Forward.”
Presenter:
Henry Swofford Ph.D. Candidate – University of Lausanne
Presentation Description:
Over the years, scientific and legal scholars have called for the implementation of algorithms (e.g., statistical methods) in forensic science to provide an empirical foundation to experts’ subjective conclusions. Despite the proliferation of numerous approaches, the practitioner community has been reluctant to apply them operationally. Reactions have ranged from passive skepticism to outright opposition, often in favor of traditional experience and expertise as a sufficient basis for conclusions.
In this webinar, we explore why practitioners are generally in opposition to algorithmic interventions and how their concerns might be overcome. We accomplish this by considering issues concerning human—algorithm interactions in both real world domains and laboratory studies as well as issues concerning the litigation of algorithms in the American legal system. Taking into account those issues, we propose a strategy for approaching the implementation of algorithms, and the different ways algorithms can be implemented, in a responsible and practical manner. To this end, we (i) outline the foundations that need to be in place from a quality assurance perspective before algorithms should be implemented, such as education, training, protocols, validation, verification, competency, and on-going monitoring schemes; and (ii) propose a formal taxonomy of six different levels of implementation ranging from Level 0 (no algorithm influence) to Level 5 (complete algorithm influence) describing various ways in which algorithms can be implemented. In levels 0 through 2, the human serves as the predominant basis for the evaluation and conclusion with increasing influence of the algorithm as a supplemental factor for quality control (used after the expert opinion has been formed). In Levels 3 through 5, the algorithm serves as the predominant basis for the evaluation and conclusion with decreasing influence from the human. We suggest a path forward is for practitioners to identify a target level of implementation that is practical given the current state of available technology and consideration of the tradeoff between the potential benefits and perceived risks for a given deployment scheme, then establish a plan for implementation that begins with Level 1 as a pilot phase and progresses sequentially through the various levels toward the target. Proceeding in this fashion will increase the likelihood for adoption across all stakeholders and lead to an overall stronger foundation and improvement to the quality and consistency of forensic science.
The webinars are free and open to the public, but researchers, collaborators and members of the broader forensics and statistics communities are encouraged to attend. Each 60-minute webinar will allow for discussion and questions.
Sign up on the form below (Chrome & Safari web browsers work the best):
On Feb. 10, the Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted the webinar, Treatment of Inconclusive Results in Error Rates of Firearms Studies. It was presented by Heike Hofmann, a professor and Kingland Faculty Fellow at Iowa State University, Susan VanderPlas, a research assistant professor at the University of Nebraska, Lincoln; and Alicia Carriquiry, CSAFE director and Distinguished Professor and President’s Chair in Statistics at Iowa State.
In the webinar, Hofmann, VanderPlas and Carriquiry revisited several Black Box studies that attempted to estimate the error rates of firearms examiners, investigating their treatment of inconclusive results. During the Q&A portion of the webinar, the presenters ran out of time to answer everyone’s questions. Hofmann, VanderPlas and Carriquiry have combined and rephrased the questions to cover the essential topics that were covered in Q&A. Their answers are below.
Is the inconclusive rate related to the study difficulty?
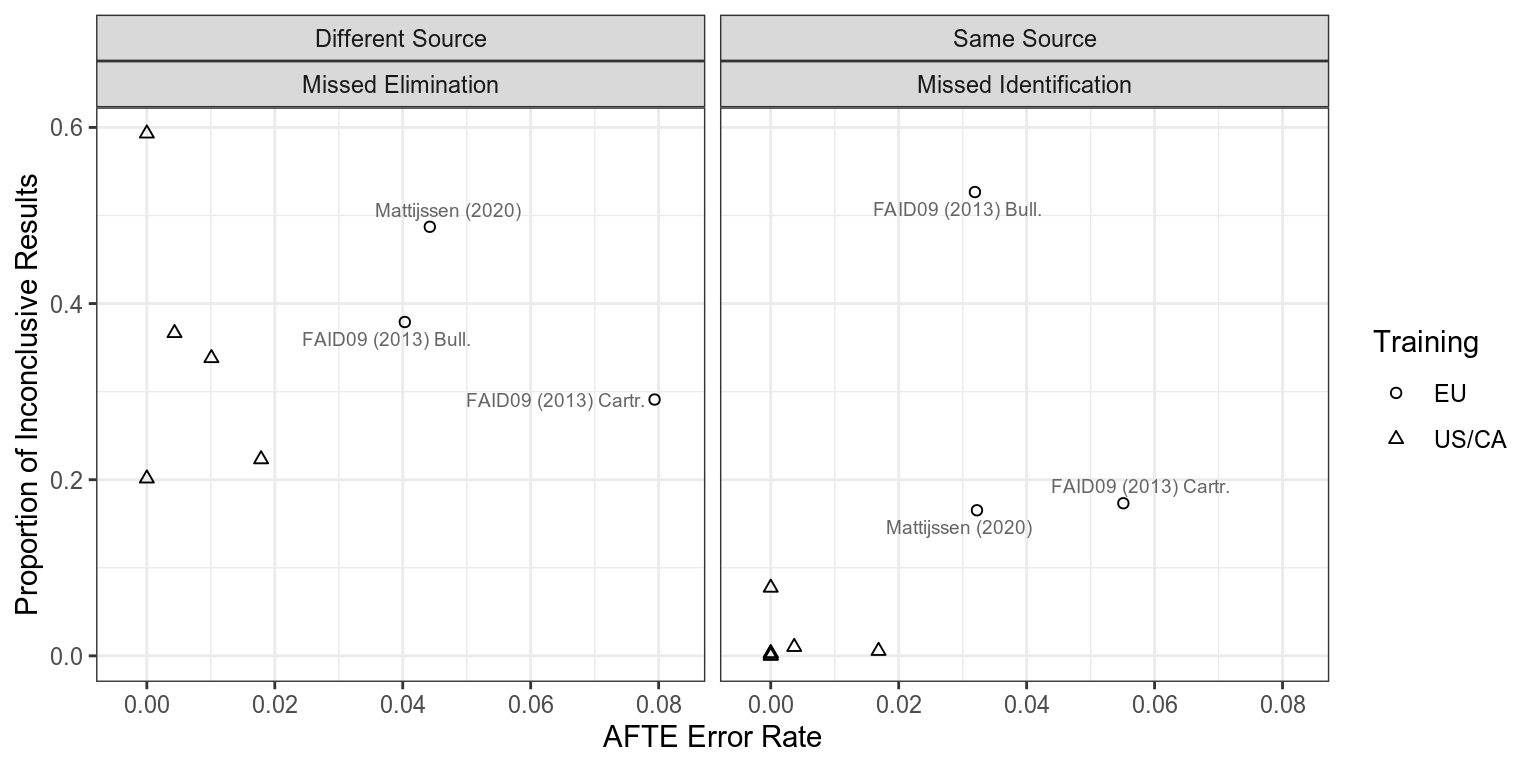
There is no doubt that we looked at several studies with different difficulty, as well as different study designs, comparison methods and examiner populations. When we examine the AFTE error rate (so only eliminations of same-source comparisons or identifications of different-source comparisons), compared to the rate of inconclusive decisions, we see that there is a clear difference between the studies conducted in Europe/U.K. and studies conducted in North America.
The EU/U.K. studies were conducted to assess lab proficiency (for the most part), and consequently, they seem to have been constructed to be able to distinguish good laboratories from excellent laboratories. So, they do include harder comparisons. The more notable result isn’t the difference in the error rates, which is relatively small; but rather, the largest difference is in the proportion of inconclusives in different-source and same-source comparisons. In the EU/U.K. studies, the proportion of inconclusives is similar for both types of comparisons. In the U.S./CA studies, the proportion of inconclusives for same-source comparisons is a fraction of the proportion of inconclusives for different-source comparisons.
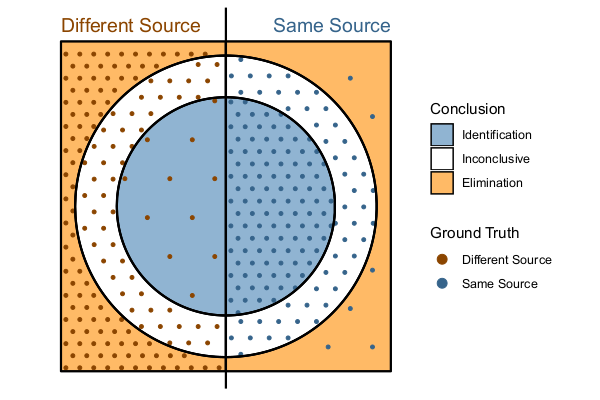
If we think about what the study results should ideally look like, we might come up with something like this:
Results of an ideal study.
In this figure, there are many different-source eliminations and same-source identifications. There are equally many same-source and different-source inconclusives, and in both cases, erroneous decisions (same-source exclusions and different-source identifications) are relatively rare. The proportion of inconclusives might be greater or smaller depending on the study difficulty or examiner experience levels, and the proportion of different-source and same-source identifications may be expected to vary somewhat depending on the study design (thus, the line down the center might shift to the left or the right). Ultimately, the entire study can be represented by this type of graphic showing the density of points in each region.
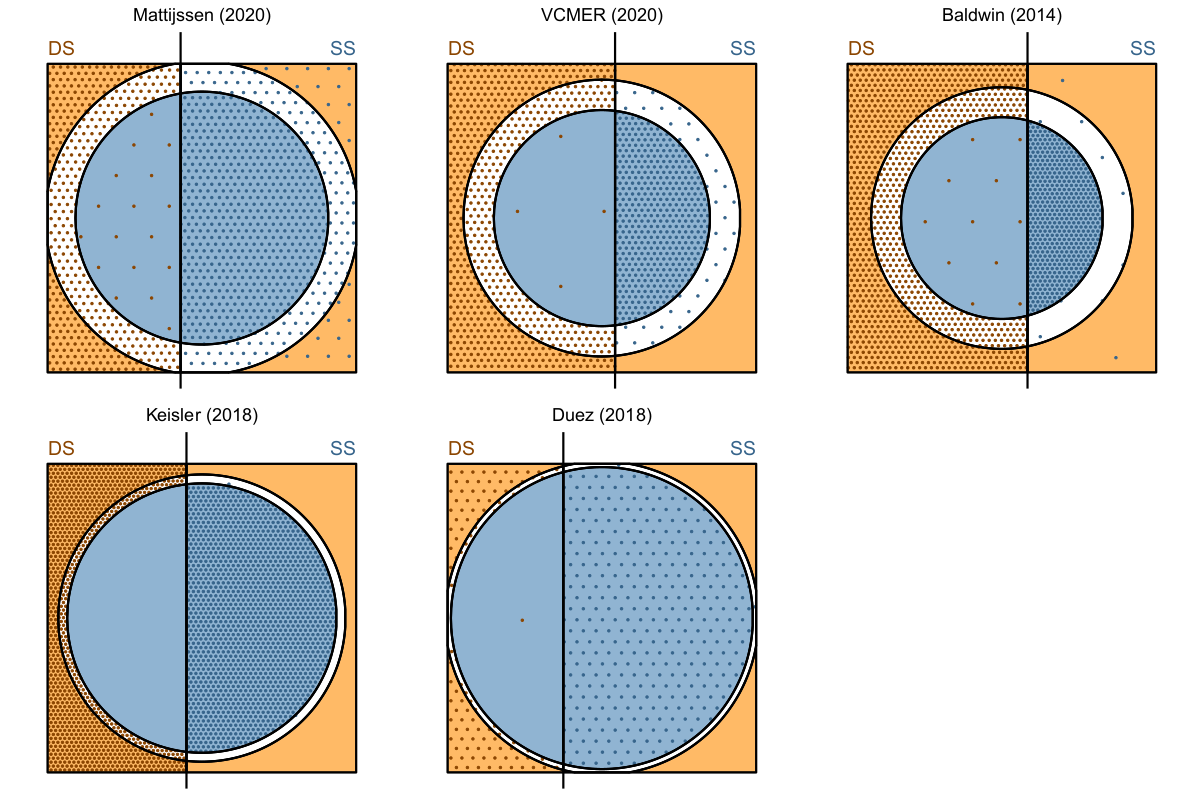
Results visualized for several different studies.
When we look at the results of several studies, we see that none of them conform precisely to this expectation. As expected, the proportion of same-source and different-source decisions vary across the studies (Baldwin includes more different-source comparisons, while Mattijssen includes more same-source comparisons), and the proportion of inconclusive results differs, with more inconclusives in the top three studies relative to Keisler and Duez. However, the most notable difference is that the proportion of inconclusive results for different-source comparisons is much higher than the proportion of inconclusive results for same-source comparisons across studies. This discrepancy is less noticeable but still present for Mattijssen (2020), which was primarily completed by EU-trained examiners. In Baldwin, Keisler and Duez, the proportion of different-source comparisons judged inconclusive makes the inconclusive category appear as an extension of the elimination—the dots have approximately the same density, and the corresponding same-source inconclusive point density is so much lower that it is nearly unnoticeable in comparison.
The real story here seems to be that while more difficult studies do seem to have slightly higher error rates (which is expected), the training, location and lab policies that influence examiner evaluations have a real impact on the proportion of inconclusive decisions which are reached. The EU/U.K. studies provide some evidence for the fact that the bias in inconclusive error rates demonstrated in our paper is a solvable problem.
Examiners often report a final answer of “inconclusive,” and this is correct according to the AFTE standard. Should inconclusives be allowed as a final answer?
From a statistical perspective, there is a mismatch between the state of reality (same source or different source) and the decision categories. This causes some difficulty when calculating error rates. We proposed multiple ways to handle this situation: using predictive probabilities, distinguishing between process error and examiner error or reframing the decision to one of identification or not-identification. Any of these options provide a much clearer interpretation of what an error is and its relevance in legal settings.
In practice, we recognize that not all evidence collected will be suitable to conclude identification or elimination due to several factors. These factors are often considered “process errors,” and examiners are trained to account for these errors and reach an inconclusive decision. We agree that this is a reasonable decision to make based on the circumstances. The issue with inconclusive decisions arises when results are presented in court, all of the errors which could contribute to the process are relevant. Thus, it is important to report the process error and the examiner-based (AFTE) error.
In some cases, however, the examiner may have noted many differences at the individual level but be uncomfortable making an elimination (in some cases, due to lab policies prohibiting elimination based on individual characteristics). That there is hesitation to make this decision is an example of the bias we have demonstrated: when there is some evidence of similarity, examiners appear to be more willing to “bet” on an identification than on an elimination based on a similar amount of dissimilarity. This higher burden of proof is an issue that has consequences for the overall error rates reported from these studies as well as the actual errors that may occur in the legal system itself.
How should courts prevent misused error rates?
The critical component to preventing misuse of error rates is to understand how error rates should be interpreted. Currently, most error rates reported include inconclusives in the denominator but not in the numerator. As we have demonstrated in our paper and this Q&A, this approach leads to error rates that are misleadingly low for the overall identification process and not actionable in a legal situation. Instead, courts should insist on predictive error rates: given the examiner’s decision, what is the probability that it resulted from a same-source or different-source comparison? These probabilities do not rely on inconclusives in the calculations and are relevant to the specific result presented by the examiner in the trial at hand.
What error rate should we use when?
The error rate we want is entirely dependent on the intended use:
In court, we should use predictive probabilities because they provide specific information which is relevant to the individual case under consideration.
In evaluating examiners, the AFTE error rates, which do not include inconclusives, may be much more useful—they identify examiner errors rather than errors that arise due to situations in which the evidence is recorded and collected. For labs, it is of eminent concern that all of their examiners are adequately trained.
It’s very important to consider the context that an error rate or probability is used and to calculate the error rate which is most appropriate for that context.
Why do you claim AFTE treats inconclusives as correct results?
In the AFTE response to the PCAST report, the response specifically discusses false identifications and false eliminations with no discussion of inconclusive results. Given that this is a foundational dispute, the way that AFTE presents these quantities in other literature is relevant, which is why we will demonstrate the problem with data pulled from AFTE’s resources for error rate calculations.
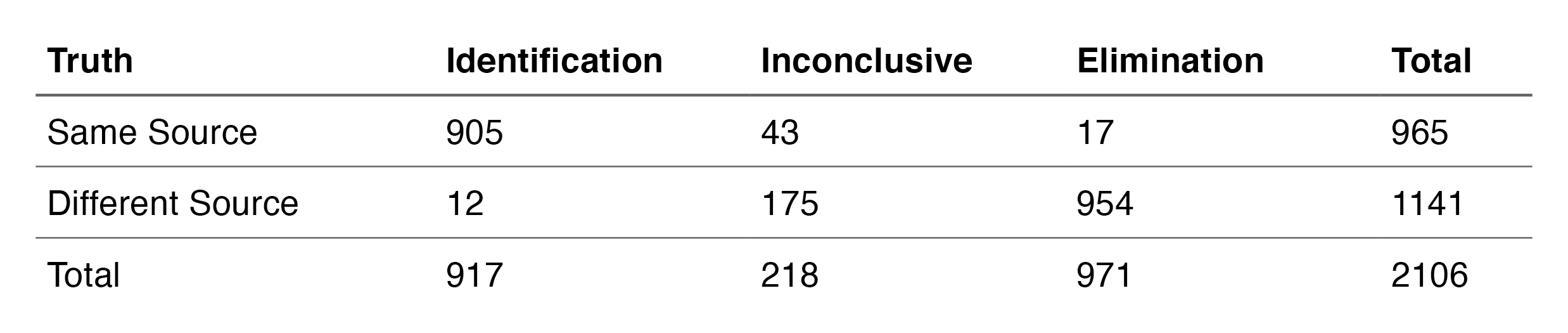
We will use the numbers on the first and second page of this document to illustrate the problem:
Bunch calculates the false-positive error rate as 12/1141 = 1.05% and the false-negative error rate as 17/965 = 1.76%. In both cases, the inconclusive decisions are included in the denominator (total evaluations) and not included in the numerator. This means that when reporting error rates, the inconclusive decisions are never counted as errors—implicitly, they are counted as correct in both cases. While he also reports the sensitivity, specificity and inconclusive rate, none of these terms are labeled as “errors,” which leads to the perception that the error rate for firearms examination is much lower than it should be.
Suppose we exclude inconclusives from the numerator and the denominator. The false-positive error rate using this approach would be 17/923 = 1.84%, and the false-negative error rate would be 12/966 = 1.24%. In both cases, this results in a higher error rate, which demonstrates that the AFTE approach to inconclusives tends to produce misleading results.
The current way errors are reported (when the reporter is being thorough) is to report the percentage of inconclusives in addition to the percentage of false eliminations and false identifications. Unfortunately, when this reporting process is followed, the discrepancy in inconclusive rates between same-source and different-source comparisons is obscured. This hides a significant source of systematic bias.
Are studies representative of casework?
First, we can’t know the answer to this question because we can’t ever know the truth in casework. This is why we have to base everything we know on designed studies because ground truth is known. So, we will never know whether the proportion of e.g., same-source and different-source comparisons in experiments is representative of casework.
What we can know, but do not yet know, is the percentage of decisions that examiners reach that are inconclusive (or identification or eliminations). We are not aware of any studies which report this data for any lab or jurisdiction. As a result, we do not know whether the proportion of inconclusive decisions is similar in casework and designed studies.
What we do know, however, is that the proportion of inconclusives is not constant between studies. In particular, there are much higher inconclusive rates for same-source comparisons in studies conducted in Europe and the U.K. These studies are intended to assess a lab’s skill and are much harder than designed error rate studies in the U.S. So, we know that the design and intent of a study do influence the inconclusive rate. More research in this area is needed.
One possibility for addressing the issue of different examiner behavior in studies versus casework is to implement widespread blind testing—testing in which the examiner is not aware they are participating in a study. The study materials would be set up to mimic evidence and the examiner would write their report as if it was an actual case. This would at least ensure that examiner behavior is similar in the study and the casework. However, this type of study is difficult to design and implement, which explains why it is not commonly done.
In one respect, studies are much harder than casework. In casework, it is much more likely that an elimination can be made on class characteristic mismatches alone. In designed studies, this is often not a scenario that is included. So, designed studies may be harder overall because they often examine consecutively manufactured (and thus more similar) firearms and toolmarks, all of which necessarily have the same class characteristics.
How do you get the predictive probability from a study?
It’s important to note that you can only get the predictive probability from a designed study. This is because you need the proportion of same-source and different-source comparisons as baseline information. These proportions are only known in designed studies and are not at all known in casework. We created a Google worksheet that can help calculate predictive probabilities and the examiner and process error rates. The worksheet is available here.
Why not just exclude inconclusives from all calculations?
One reason is that inconclusive results are still reported in legal settings, but they are not equally likely when examining same-source and different-source evidence, which is informative. Given that an examiner reports an inconclusive result, the source is much more likely to be different than the same. By ignoring inconclusives entirely, we would be throwing out data that is informative. This argument has been made by Biedermann et al., but they did not take the assertion to its obvious conclusion.
What about lab policies that prohibit elimination on individual characteristics?
First, those policies are in direct conflict with the AFTE range of conclusions as published at https://afte.org/about-us/what-is-afte/afte-range-of-conclusions. These guidelines specify “Significant disagreement of discernible class characteristics and/or individual characteristics.” as a reason for an elimination. An interpretation by labs that does not have an elimination based on individual characteristics should be addressed and clarified by AFTE.
Those policies also introduce bias into the examiner’s decision. As can be seen from the rate at which inconclusive results stem from different-source comparisons in case studies, almost all inconclusive results are from different-source comparisons. Some studies controlled for this policy by asking participants to follow the same rules, and even in these studies, the same bias against same-source comparisons being labeled as inconclusive is present. This is true in Bunch and Murphy (conducted at the FBI lab, which has such a policy) and is also true in Baldwin, which was a much larger and more heterogeneous study that requested examiners make eliminations based on individual characteristic mismatches.
A finding of “no identification” could easily be misinterpreted by a non-firearms examiner, such as a juror or attorney, as an elimination.
Under the status quo, an inconclusive can easily be framed as an almost-identification; so, this ambiguity is already present in the system, and we rely on attorneys to frame the issue appropriately for the judge and/or jury. Under our proposal to eliminate inconclusives, we would also have to rely on attorneys to correctly contextualize the information presented by the examiner.
You say that inconclusive results occur more frequently when the conclusion is different-source. Could a conviction occur based on an inconclusive result? Why is this an issue?
Probably not, unless the testimony was something like, “I see a lot of similarities, but not quite enough to establish an identification.” The framing of the inconclusive is important, and at the moment, there is no uniformity in how these results are reported.