The National Institute of Standards and Technology (NIST) has begun work on a new Scientific Foundation Review for footwear impression examination and will hold a workshop on this review at the 2023 International Association for Identification (IAI) Annual International Forensic Educational Conference.
The IAI Conference will be held Aug. 20-26 in National Harbor, Maryland, and the NIST-hosted workshop, “Footwear Impression Examination: A NIST Scientific Foundation Review,” will take place Aug. 25 from 10 a.m.-3 p.m. EDT.
NIST Scientific Foundation Reviews document and evaluate the scientific basis for forensic science methods and practices. These reviews focus on the published scientific literature and other relevant sources of data that can provide information on questions of reliability. To date, NIST has begun or completed reviews on DNA mixture interpretation, digital evidence, bitemark analysis and firearms examination.
The workshop at the IAI Conference will explore key questions, premises and knowledge gaps in forensic footwear examination to inform a Scientific Foundation Review of the practice. Participants will hear about progress and plans for this review and can provide feedback on the literature gathered and identified claims for the field. This workshop is part of a study that will culminate with a public report from NIST regarding scientific foundations for performing forensic footwear examinations.
The workshop will be led by Kelly Sauerwein, a physical scientist with the Forensic Science Research Program in the NIST Special Programs Office, and John Butler, a NIST Fellow and Special Assistant to the Director for Forensic Science in the NIST Special Programs Office.
For questions about the workshop or information on potential travel support, contact Sauerwein at kelly.sauerwein@nist.gov.
The National Institute of Standards and Technology (NIST) will host a webinar to discuss its latest Scientific Foundation Review on bitemark analysis. The webinar will be held Oct. 27 from 1–3 p.m. EDT.
NIST Scientific Foundation Reviews document and evaluate the scientific basis for forensic science methods and practices. These reviews focus on the published scientific literature and other relevant sources of data that can provide information on questions of reliability. To date, NIST has begun foundation reviews on DNA mixture interpretation, digital evidence, bitemark analysis, and firearms examination.
The upcoming webinar will review the contents and findings in a draft report, Bitemark Analysis: A NIST Scientific Foundation Review, and provide an opportunity for attendees to ask questions. The draft report will be open for public comment through Dec. 12, 2022. The authors will consider all comments submitted before publishing a final version of the report. For more information
The Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted a workshop in 2019 where forensic dentists, researchers, statisticians, lawyers and other experts addressed scientific questions around bitemark analysis. A summary of the workshop was written by Alicia Carriquiry, CSAFE director, and Hal Stern, CSAFE co-director. It provided information for the NIST review and has been published as a supplement to it.
In the webinar, Neuman shares the methodology for HSFC’s blind proficiency testing program, as well as results from a recent study of 51 blind cases submitted to examiners between 2015 and 2021.
If you did not attend the webinar live, the recording is available at https://forensicstats.org/blog/portfolio/blind-testing-in-firearms-examination/
Why is blind testing important?
If an examiner knows they are being tested, results from a study can be skewed, so several governing bodies in the forensic science community recommend conducting blind proficiency tests to achieve more precise results. Researchers can do this by inserting test samples into the flow of casework so examiners do not know that they are being tested.
HSFC implemented its blind quality control program in 2015 and creates mock case evidence in house, with the goal of submitting test material at a rate of five percent of each section’s output from the year before.
Why is the advantage of having a blind testing program?
The biggest advantage is having a ground truth against which to compare examination results, which is not known in normal casework. Additionally, because examiners aren’t aware which cases are test cases, they perform the work as they would for a normal case. This allows researchers to observe the entire examination process, from evidence submission to the reporting of results.
How are firearms blind cases designed and submitted?
Blind cases mimic routine evidence and cases in order to appear authentic. The firearm used to create the fired evidence may or may not be submitted as an additional piece of evidence. Though HFSC has a large reference collection, blind tests are not created from this library as the examiners are likely to recognize the evidence. Some fired evidence is created using personal firearms from employees of HFSC.
HFSC researchers have also developed a partnership with the Houston Police Department (HPD), and regularly use firearms the property room division has slated for destruction to create mock evidence for blind testing. These firearms are often representative of the types of firearms seen frequently in casework.
Fired evidence is then marked or documented in a way that relates it back to its corresponding firearm. Cartridge casings and bullet jackets are submitted with ground truths of either identification or elimination. Fragments and bullet cores are expected to be unsuitable or insufficient regardless of which firearm was used to create the evidence.
When a case is ready, it is packaged just like a regular firearms case would be, in an envelope or gun box. Technicians take the evidence to the HPD property room and prepare it with an HPD evidence bar code. The evidence stays there until HFSC makes a request for analysis, enlisting the help of HPD officers who use their names on the request, thus keeping the test blind. When the evidence arrives at HFSC for processing, it is assigned as usual by managers and supervisors who themselves do not know which evidence is real casework and which is test material.
What are the range of results expected from a blind proficiency firearms test?
The range of results expected in HSFC’s blind proficiency test program follow the standard operating procedures widely used within the community. A condensed version of the results expected include:
What are the objectives of HFSC’s blind proficiency tests?
What were the parameters and results of HSFC’s most recent study?
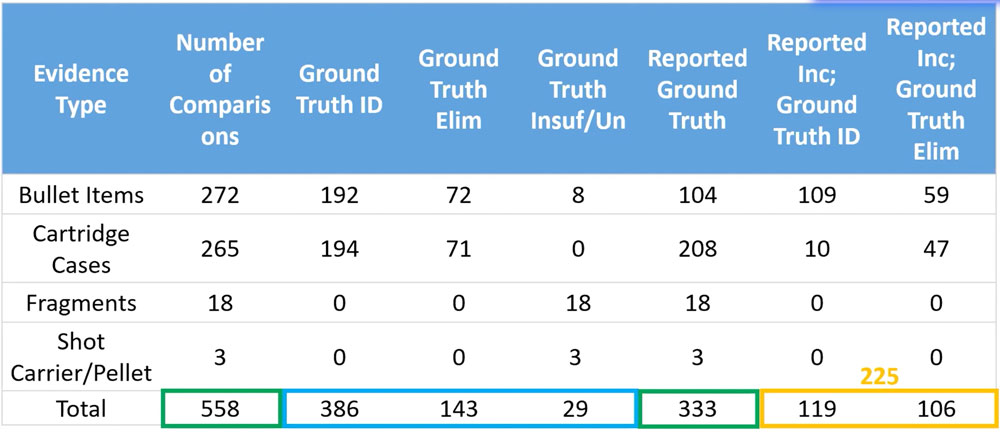
Test results were received from December 2015 to June 2021.
51 cases were reported.
460 items were examined.
570 sufficiency and comparison conclusions were submitted, including:
386 identification
143 elimination
29 insufficient/unsuitable
12 items eliminated from study because ground truth could not be re-established after examination.
11 examiners
Preliminary results
What are some trends in the results?
There was a 40 percent inconclusive rate throughout the course of the study.
There was a higher rate of inconclusive results when the ground truth was elimination (74 percent of elimination results reported inconclusive) as opposed a ground truth of identification (31 percent of identification results reported as inconclusive).
Bullets had a higher inconclusive rate than cartridge cases (62 versus 22 percent).
Inconclusive decisions were made in 86 percent of comparisons in which the evidence was created using two firearms of the same class.
Inconclusive decisions did not appear to be related to examiner pairings, experience, or the examiner’s training program.
What are the benefits of blind testing?
Blind tests provide a more controlled environment in which to examine inconclusive results.
Blind testing can gauge proficiencies in areas that normal proficiency tests don’t always cover (e.g., including evidence spanning cartridge cases, bullets, fragments, and firearms rather than just bullets or cartridge cases).
More challenging case scenarios can be created to test the examiners’ thresholds for conclusions.
Citing blind proficiency test results gives examiners the opportunity to bolster their credibility in court.
What are the next steps for HSFC’s blind testing program?
In the next phase of HSFC’s blind testing program, researchers would like to:
Compare the program’s inconclusive rates to those found in real casework.
Examine the consultation rate in the blind verification program.
Use blind cases for training new examiners and assessing new technology.
Collaborate with other labs and researchers to further this research.
On April 22, the Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted the webinar, Shining a Light on Black Box Studies. It was presented by Dr. Kori Khan, an assistant professor in the department of statistics at Iowa State University, and Dr. Alicia Carriquiry,
CSAFE director and Distinguished Professor and President’s Chair in Statistics at Iowa State.
In the webinar, Khan and Carriquiry used two case studies—the Ames II ballistics study and a palmar prints study by Heidi Eldridge, Marco De Donno, and Christophe Champod (referred to in the webinar as the EDC study)—to illustrate the common problems of examiner representation and high levels of non-response (also called missingness) in Black Box studies, as well as recommendations for addressing these issues in the future.
To start to understand Black Box studies, we must first establish foundational validity. The 2016 PCAST report brought Black Box studies into focus and defined them to be a thing of interest. The report detailed that in order for these feature comparison types of disciplines, we need to establish foundational validity, which means that empirical studies must show that, with known probability:
An examiner obtains correct results for true positives and true negatives.
An examiner obtains the same results when analyzing samples from the same types of sources.
Different examiners arrive at the same conclusions.
What is a Black Box Study?
The PCAST report proposed that the only way to establish foundational validity for feature comparison methods that rely on some amount of objective determination is through multiple, independent Black Box studies. In these studies, the examiner is supposed to be considered a “Black Box,” meaning there is some amount of subjective determination.
Method: Examiners are given test sets and samples and asked to render opinions about what their conclusion would have been if this was actual casework. Examiners are not asked about how they arrive at these conclusions. Data is collected and analyzed to establish accuracy. In a later phase, participants are given more data and their responses are again collected and then measured for repeatability and reproducibility.
Goal: The goal with Black Box studies is to analyze how well the examiners perform in providing accurate results. Therefore, in these studies, it is essential that ground truth be known with certainty.
What are the common types of measures in Black Box studies?
The four common types of measures are False Positive Error Rate (FPR), False Negative Error Rate (FNR), Sensitivity, and Specificity. Inconclusives are generally excluded from Black Box studies as neither an incorrect identification or incorrect exclusions, so inconclusive decisions are not treated as errors.
What are some common problems in some existing Black Box studies?
Representative Samples of Examiners
In order for results to reflect real-world scenarios, we need to ensure that the Black Box volunteer participants are representative of the population of interest. In an ideal scenario, volunteers are pulled from a list of persons within the population of interest, though this is not always possible.
All Black Box studies rely on volunteer participation, which can lead to self-selection bias, meaning those who volunteer are different from those who don’t. For example, perhaps those who volunteer are less busy than those who don’t volunteer. Therefore, it’s important that Black Box studies have inclusion criteria to help make the volunteer set as representative of the population of interest as possible.
In the Ames II case study, volunteers were solicited through the FBI and the Association of Firearm and Toolmarks (AFTE) contact list. Participants were limited by the following criteria:
Problems with this set:
Many examiners do not work for an accredited U.S. public crime laboratory.
Many examiners are not current members of AFTE.
Overall, this is strong evidence in this study that the volunteer set does not match or represent the population of interest, which can negatively influence the accuracy of Black Box study results.
Handling Missing Data
Statistical literature has many rules of thumb stating that it is okay to carry out statistical analyses on the observed data if the missing data accounts for between 5–20% and the missingness is “ignorable”. If missingness is non-ignorable, any amount of missingness can bias estimates. Across most Black Box studies, missing data is between 30–40%. We can adjust for some non-response, but first we must know whether it’s ignorable or non-ignorable.
Adjusting for missing data depends on the missingness mechanism (potentially at two levels: unit and item).
Ignorable:
Missing Completely at Random: the probability that any observation is missing doew not depend on any other variable in the dataset (observed or unobserved)
Missing at Random: the probability that any observation is missing only depends on other observed variables.
Non-ignorable
Not Missing at Random (NMAR): The probability that any observation is missing depends on unobserved values. Also know as non-ignorable.
To make this determination, the following data at a minimum must be known:
The participants who enrolled and did not participate
The participants who enrolled and did participate
Demographics for each of these groups of examiners
The total number of test sets and types assigned to each examiner
For each examiner, a list of the items he/she did or did not answer
For each examiner, a list of the items he/she did or did not correctly answer
Most Black Box studies do not release this information or the raw data. For example:
However, study made much of the necessary data known, allowing researchers to study missingness empirically. If there is a characteristic of examiners that is associated with higher error rates, and if that characteristic is also associated with higher levels of missingness, we have evidence that the missingness is non-ignorable and can come up with ways to address it.
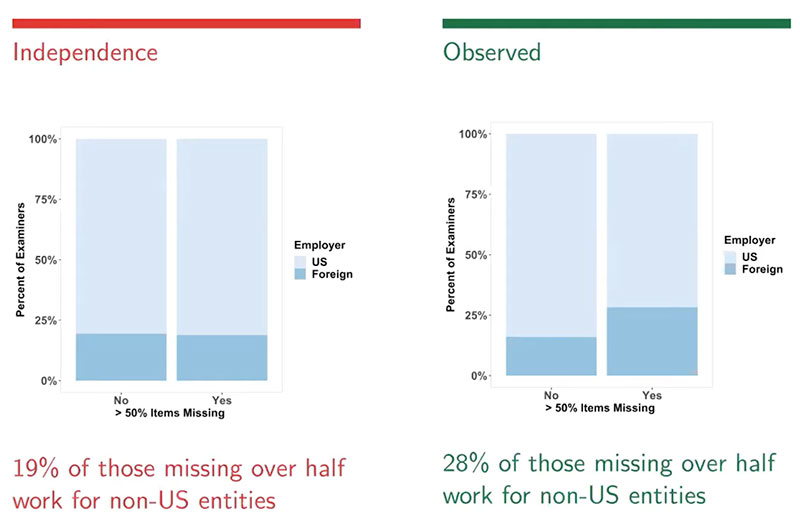
In this example, of the 226 examiners who returned some test sets in the studies, 197 of those also had demographic information. Of those 197, 53 failed to render a decision for over half of the 75 tests presented to them. The EDC study noted that examiners who worked for non-U.S. entities committed 50% of the false positives made in the study, but only accounted for less than 20% of the examiners. Researchers wanted to discover whether examiners who worked for non-U.S. entities had higher rates of missingness. After analyzing the data, researchers found that instead of the 19% of respondents that worked for non-U.S. entities that were expected to have a missingness of over half, the observed amount was 28% of respondents.
Researchers then conducted a hypothesis test to see if there was an association between working for a non-U.S. entity and missingness by taking a random sample size, calculating the proportion of foreign workers in the sample, repeating many times, and comparing the observed value of 28% to the calculated ones.
H0: Working for a non-US entity is statistically independent of missingness
HA: Working for a non-US entity is associated with a higher missingness
Using this method, researchers found that the observed result (28%) would occur only 4% of the time, if there was no relationship between missingness and working for a non-U.S. entity, meaning that there is strong evidence that working for a non-U.S. entity is associated with higher missingness.
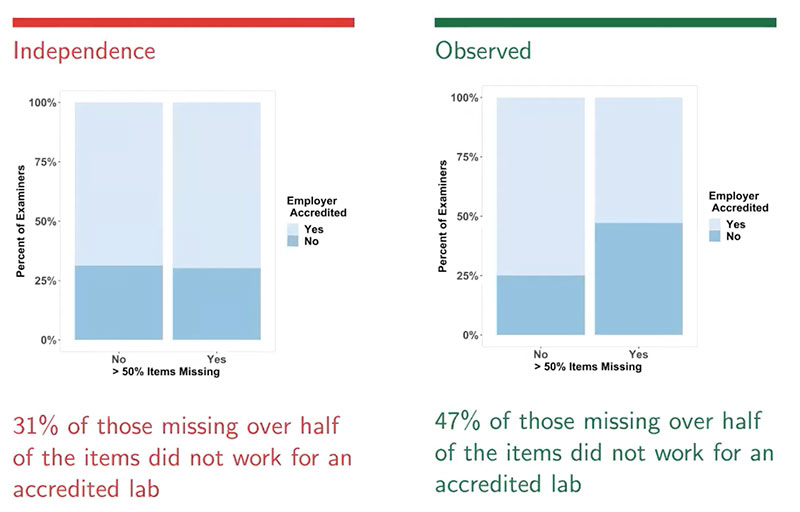
Researchers repeated the process to test whether missingness is higher among examiners who did not work for an accredited lab and had similar findings:
In this case, the hypothesis showed that his result (47% missingness) would only be expected about 0.29% of the time. Therefore, there is strong evidence that working for an unaccredited lab is associated with a higher missingness.
What are the next steps for gaining insights from Black Box studies?
The two issues discussed in this webinar—lack of a representative sample of participants and non-ignorable non-response—can be addressed in the short term with minor funding and cooperation among researchers.
Representation
Draw a random sample of courts (state, federal, nationwide, etc.)
Enumerate experts in each
Stratify and sample experts
Even if the person refuses to participate, at least we know in which ways (education, gender, age, etc.) the participants are or are not representative of the population of interest.
Missingness
This is producing the biggest biases in the studies that have been published.
Adjusting for non-response is necessary for the future of Black Box studies.
Results can be adjusted if those who conduct the studies release more data and increase transparency to aid collaboration.
Longer term solutions include:
Limiting who qualifies as an “expert” when testifying in court (existing parameters require minimal little to no certification, education, or testing)
Institutionalized, regular discipline-wide testing with expectations of participation.
Requirements to share data from Black Box studies in more granular form.
According to the AAFS news release, “Training will address technical aspects of the standards as well as challenges, practical solutions and benefits of adoption. Resources, including auditing checklists for compliance monitoring and gap analysis, will also be developed, as well as factsheets, understandable to the layperson.”
AAFS said these resources would help advance the implementation of standards and guidelines listed on the Organization of Scientific Area Committees (OSAC) for Forensic Science’s Registry.
The webpage includes information about the cooperative agreement, upcoming webinars, videos on the standards, standards checklists (coming soon) and the AAFS Standards Factsheets.
The AAFS Standards Factsheets provide a summary of each standard and highlight its purpose, why it is important, and what its benefits are. AAFS notes that the factsheets are in continuous production, and more will come soon. There are currently 12 published factsheets available to download.
The factsheets include:
ANSI/ASB Standard 018 Standard for Validation of Probabilistic Genotyping Systems
ANSI/ASB Standard 020 Standard for Validation Studies of DNA Mixtures, and Development and Verification of a Laboratory’s Mixture Interpretation Protocol
ANSI/ASB Standard 036 Standard Practices for Method Validation in Forensic Toxicology
ANSI/ASB Standard 037 Guidelines for Opinions and Testimony in Forensic Toxicology
ANSI/ASB Standard 040 Standard for Forensic DNA Interpretation and Comparison Protocols
ANSI/ASB Standard 061 Firearms and Toolmarks 3D Measurement Systems and Measurement Quality Control
ASTM E2329-17 Standard Practice for Identification of Seized Drugs
ASTM E2548-16 Standard Guide for Sampling Seized Drugs for Qualitative and Quantitative Analysis
ASTM E3245-20e1 Standard Guide for Systematic Approach to the Extraction, Analysis, and Classification of Ignitable Liquids and Ignitable Liquid Residues in Fire Debris Samples
ASTM E3260-21 Standard Guide for forensic Examination and Comparison of Pressure Sensitive Tapes
NFPA-921 Guide to Fire and Explosion Investigations
NFPA-1033 Standard for Professional Qualifications for Fire Investigations
The Center for Statistics and Applications in Forensic Evidence (CSAFE), a NIST Center of Excellence, has several researchers who serve on the OSAC Forensic Science Standards Board (FSSB), subcommittees and resource task groups, including Jeff Salyards, a CSAFE research scientist, who serves as an FSSB member at large, and Danica Ommen, a CSAFE researcher, who serves as the chair of the Statistics Task Group. Learn more about how these groups help the development of scientifically sound standards and guidelines for the forensic science community at https://www.nist.gov/osac/osac-organizational-structure.
The American Society of Crime Laboratory Directors (ASCLD) Forensic Research Committee (FRC) works to identify the research, development, technology and evaluation needs and priorities for the forensic science community. The FRC has several initiatives and resources available on its website to aid both researchers and practitioners. Below, we highlight a few of those resources.
The FRC collaboration hub hosts the Researcher-Practitioner Collaboration Directory. The directory helps connect researchers with ongoing projects to practitioners who are willing to participate in the studies. The searchable directory includes descriptions of each project, including an abstract and the estimated participant time involved. Researchers can easily submit their projects for inclusion in the directory by completing an online form.
The FRC hosts a virtual “Lightning Talks” series to highlight new and emerging research in all areas of forensic science. Each episode features three short talks given by practitioners, researchers or students. Previous Lightning Talks are archived on FRC’s YouTube page.
Laboratories and Educators Alliance Program (LEAP)
LEAP facilitates collaborative research between academia and forensic science laboratories. This program identifies forensic science needs and provides a platform for laboratories, researchers and students to seek projects aligning with their mutual research capabilities. The FRC website includes a map of LEAP partners, a short video explaining LEAP and sign-up forms for crime labs and universities. LEAP is a joint effort between ASCLD and the Council of Forensic Science Educators (COFSE).
Validation and Evaluation Repository
The Validation and Evaluation Repository is a list of unique validations and evaluations conducted by forensic labs and universities. ASCLD’s summary of the repository states, “It is ASCLD’s hope that this listing will foster communication and reduce unnecessary repetition of validations and evaluations to benefit the forensic community.” The searchable repository is available at https://www.ascld.org/validation-evaluation-repository/
Research Executive Summaries
The Future Forensics Subcommittee of the FRC has initiated the publication of brief executive summaries of the recent literature within the forensic sciences. The summaries are written by ASCLD members and are meant to provide a brief overview of noteworthy publications and trends in the literature. Currently, the summaries include reviews in the areas of fingermarks, controlled substances, paint and glass evidence, forensic toxicology, forensic biology, gunshot residue analysis and firearms and toolmarks.
A new study assessing the accuracy and reproducibility of practicing bloodstain pattern analysts’ conclusions will be the focus of an upcoming Center for Statistics and Applications in Forensic Evidence (CSAFE) webinar.
During the webinar, Austin Hicklin, director at the Forensic Science Group; Paul Kish, a forensic consultant; and Kevin Winer, director at the Kansas City Police Crime Laboratory, will discuss their recently published article, Accuracy and Reproducibility of Conclusions by Forensic Bloodstain Pattern Analysts. The article was published in the August issue of Forensic Science International.
From the Abstract:
Although the analysis of bloodstain pattern evidence left at crime scenes relies on the expert opinions of bloodstain pattern analysts, the accuracy and reproducibility of these conclusions have never been rigorously evaluated at a large scale. We investigated conclusions made by 75 practicing bloodstain pattern analysts on 192 bloodstain patterns selected to be broadly representative of operational casework, resulting in 33,005 responses to prompts and 1760 short text responses. Our results show that conclusions were often erroneous and often contradicted other analysts. On samples with known causes, 11.2% of responses were erroneous. The results show limited reproducibility of conclusions: 7.8% of responses contradicted other analysts. The disagreements with respect to the meaning and usage of BPA terminology and classifications suggest a need for improved standards. Both semantic differences and contradictory interpretations contributed to errors and disagreements, which could have serious implications if they occurred in casework.
The study was supported by a grant from the U.S. National Institute of Justice. Kish and Winer are members of CSAFE’s Research and Technology Transfer Advisory Board.
The CSAFE Fall 2021 Webinar Series is sponsored by the National Institute of Standards and Technology (NIST) through cooperative agreement 70NANB20H019.
CSAFE researchers are also undertaking projects to develop objective analytic approaches to enhance the practice of bloodstain pattern analysis. Learn more about CSAFE’s BPA projects at forensicstats.org/blood-pattern-analysis.
Plan to attend the Organization of Scientific Area Committees (OSAC) for Forensic Science Public Update Meeting on Sept. 29, 2021, from 1–4:30 p.m. EDT.
This virtual event will feature presentations from the chairs of OSAC’s Forensic Science Standards Board and seven Scientific Area Committees. Each presenter will describe the standards their unit is working on and discuss research gaps, challenges, and priorities for the coming year. Attendees will have the opportunity to ask questions and provide feedback. There is no fee to attend, but registration is required.
OSAC works to strengthen forensic science by facilitating the development of technically sound standards and promoting the use of those standards by the forensic science community. OSAC’s 800-plus members and affiliates draft and evaluate forensic science standards through a transparent, consensus-based process that allows for participation and comment by all stakeholders. For more information about OSAC and its programs, visit https://www.nist.gov/osac.
The meeting agenda and registration information is available on the OSAC website.
On Feb. 10, the Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted the webinar, Treatment of Inconclusive Results in Error Rates of Firearms Studies. It was presented by Heike Hofmann, a professor and Kingland Faculty Fellow at Iowa State University, Susan VanderPlas, a research assistant professor at the University of Nebraska, Lincoln; and Alicia Carriquiry, CSAFE director and Distinguished Professor and President’s Chair in Statistics at Iowa State.
In the webinar, Hofmann, VanderPlas and Carriquiry revisited several Black Box studies that attempted to estimate the error rates of firearms examiners, investigating their treatment of inconclusive results. During the Q&A portion of the webinar, the presenters ran out of time to answer everyone’s questions. Hofmann, VanderPlas and Carriquiry have combined and rephrased the questions to cover the essential topics that were covered in Q&A. Their answers are below.
Is the inconclusive rate related to the study difficulty?
There is no doubt that we looked at several studies with different difficulty, as well as different study designs, comparison methods and examiner populations. When we examine the AFTE error rate (so only eliminations of same-source comparisons or identifications of different-source comparisons), compared to the rate of inconclusive decisions, we see that there is a clear difference between the studies conducted in Europe/U.K. and studies conducted in North America.
The EU/U.K. studies were conducted to assess lab proficiency (for the most part), and consequently, they seem to have been constructed to be able to distinguish good laboratories from excellent laboratories. So, they do include harder comparisons. The more notable result isn’t the difference in the error rates, which is relatively small; but rather, the largest difference is in the proportion of inconclusives in different-source and same-source comparisons. In the EU/U.K. studies, the proportion of inconclusives is similar for both types of comparisons. In the U.S./CA studies, the proportion of inconclusives for same-source comparisons is a fraction of the proportion of inconclusives for different-source comparisons.
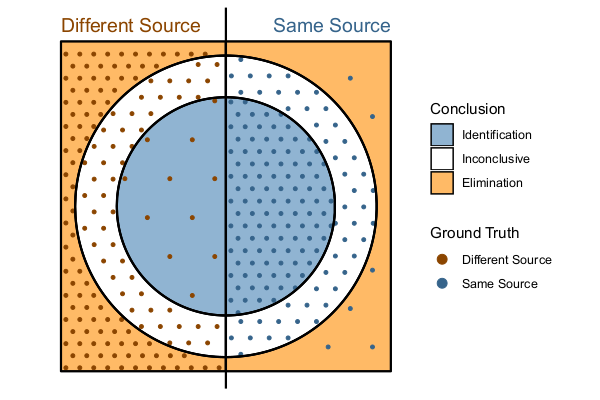
If we think about what the study results should ideally look like, we might come up with something like this:
Results of an ideal study.
In this figure, there are many different-source eliminations and same-source identifications. There are equally many same-source and different-source inconclusives, and in both cases, erroneous decisions (same-source exclusions and different-source identifications) are relatively rare. The proportion of inconclusives might be greater or smaller depending on the study difficulty or examiner experience levels, and the proportion of different-source and same-source identifications may be expected to vary somewhat depending on the study design (thus, the line down the center might shift to the left or the right). Ultimately, the entire study can be represented by this type of graphic showing the density of points in each region.
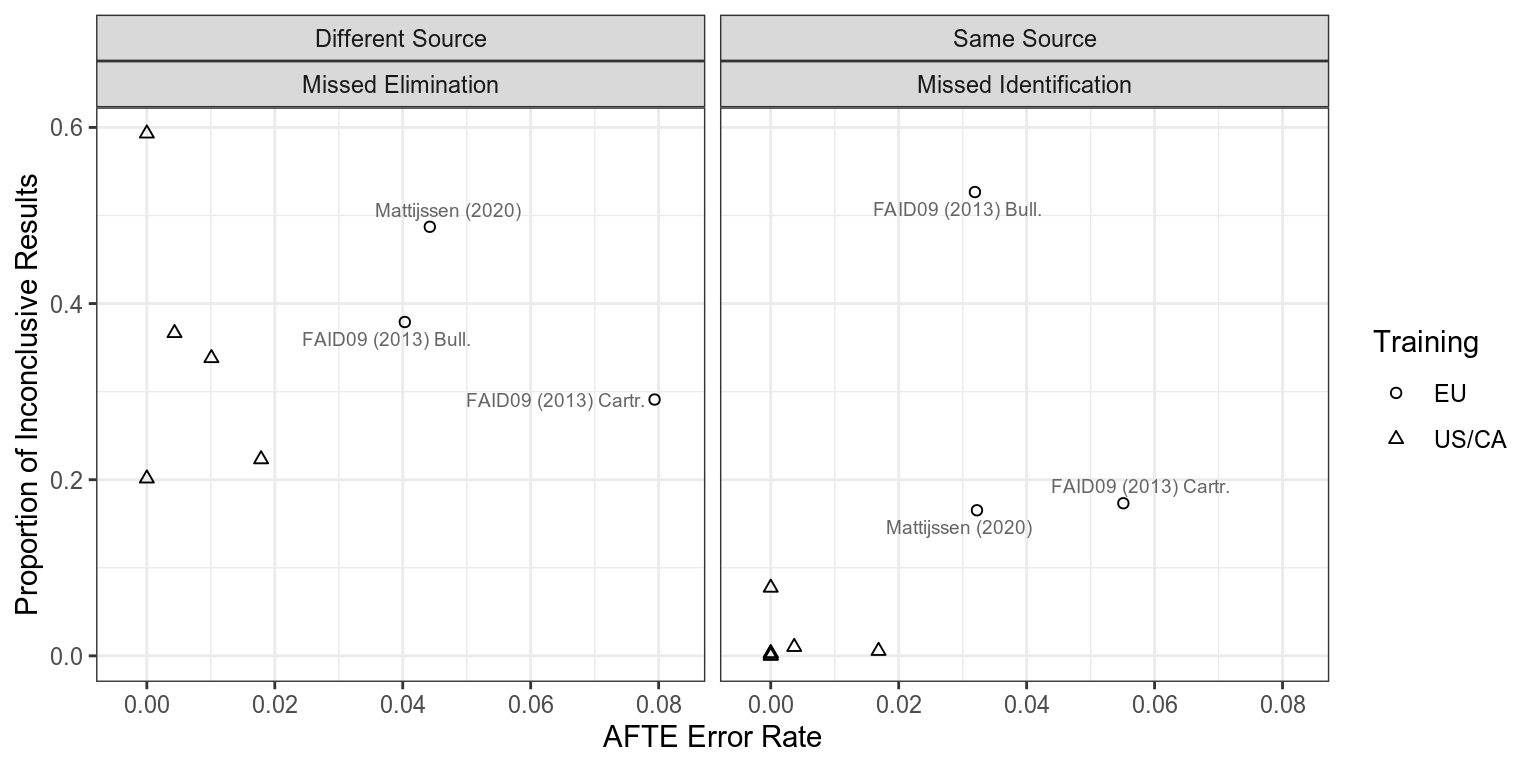
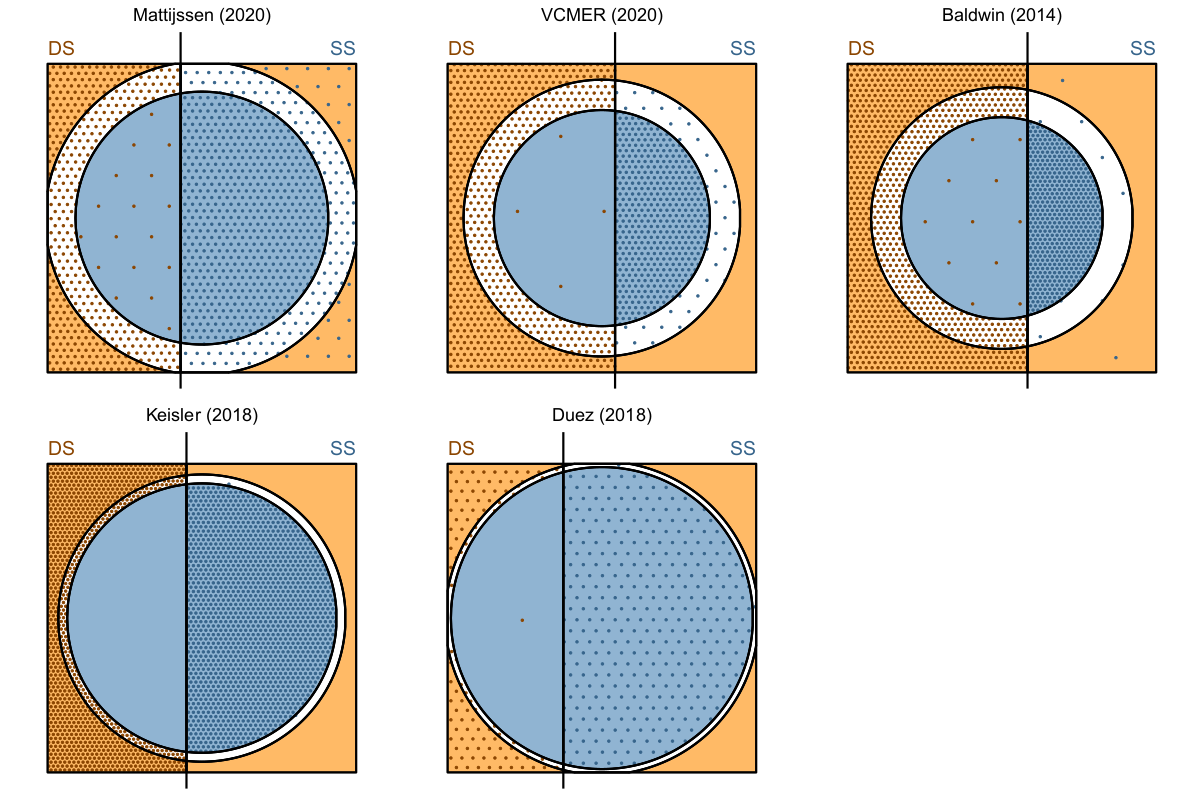
Results visualized for several different studies.
When we look at the results of several studies, we see that none of them conform precisely to this expectation. As expected, the proportion of same-source and different-source decisions vary across the studies (Baldwin includes more different-source comparisons, while Mattijssen includes more same-source comparisons), and the proportion of inconclusive results differs, with more inconclusives in the top three studies relative to Keisler and Duez. However, the most notable difference is that the proportion of inconclusive results for different-source comparisons is much higher than the proportion of inconclusive results for same-source comparisons across studies. This discrepancy is less noticeable but still present for Mattijssen (2020), which was primarily completed by EU-trained examiners. In Baldwin, Keisler and Duez, the proportion of different-source comparisons judged inconclusive makes the inconclusive category appear as an extension of the elimination—the dots have approximately the same density, and the corresponding same-source inconclusive point density is so much lower that it is nearly unnoticeable in comparison.
The real story here seems to be that while more difficult studies do seem to have slightly higher error rates (which is expected), the training, location and lab policies that influence examiner evaluations have a real impact on the proportion of inconclusive decisions which are reached. The EU/U.K. studies provide some evidence for the fact that the bias in inconclusive error rates demonstrated in our paper is a solvable problem.
Examiners often report a final answer of “inconclusive,” and this is correct according to the AFTE standard. Should inconclusives be allowed as a final answer?
From a statistical perspective, there is a mismatch between the state of reality (same source or different source) and the decision categories. This causes some difficulty when calculating error rates. We proposed multiple ways to handle this situation: using predictive probabilities, distinguishing between process error and examiner error or reframing the decision to one of identification or not-identification. Any of these options provide a much clearer interpretation of what an error is and its relevance in legal settings.
In practice, we recognize that not all evidence collected will be suitable to conclude identification or elimination due to several factors. These factors are often considered “process errors,” and examiners are trained to account for these errors and reach an inconclusive decision. We agree that this is a reasonable decision to make based on the circumstances. The issue with inconclusive decisions arises when results are presented in court, all of the errors which could contribute to the process are relevant. Thus, it is important to report the process error and the examiner-based (AFTE) error.
In some cases, however, the examiner may have noted many differences at the individual level but be uncomfortable making an elimination (in some cases, due to lab policies prohibiting elimination based on individual characteristics). That there is hesitation to make this decision is an example of the bias we have demonstrated: when there is some evidence of similarity, examiners appear to be more willing to “bet” on an identification than on an elimination based on a similar amount of dissimilarity. This higher burden of proof is an issue that has consequences for the overall error rates reported from these studies as well as the actual errors that may occur in the legal system itself.
How should courts prevent misused error rates?
The critical component to preventing misuse of error rates is to understand how error rates should be interpreted. Currently, most error rates reported include inconclusives in the denominator but not in the numerator. As we have demonstrated in our paper and this Q&A, this approach leads to error rates that are misleadingly low for the overall identification process and not actionable in a legal situation. Instead, courts should insist on predictive error rates: given the examiner’s decision, what is the probability that it resulted from a same-source or different-source comparison? These probabilities do not rely on inconclusives in the calculations and are relevant to the specific result presented by the examiner in the trial at hand.
What error rate should we use when?
The error rate we want is entirely dependent on the intended use:
In court, we should use predictive probabilities because they provide specific information which is relevant to the individual case under consideration.
In evaluating examiners, the AFTE error rates, which do not include inconclusives, may be much more useful—they identify examiner errors rather than errors that arise due to situations in which the evidence is recorded and collected. For labs, it is of eminent concern that all of their examiners are adequately trained.
It’s very important to consider the context that an error rate or probability is used and to calculate the error rate which is most appropriate for that context.
Why do you claim AFTE treats inconclusives as correct results?
In the AFTE response to the PCAST report, the response specifically discusses false identifications and false eliminations with no discussion of inconclusive results. Given that this is a foundational dispute, the way that AFTE presents these quantities in other literature is relevant, which is why we will demonstrate the problem with data pulled from AFTE’s resources for error rate calculations.
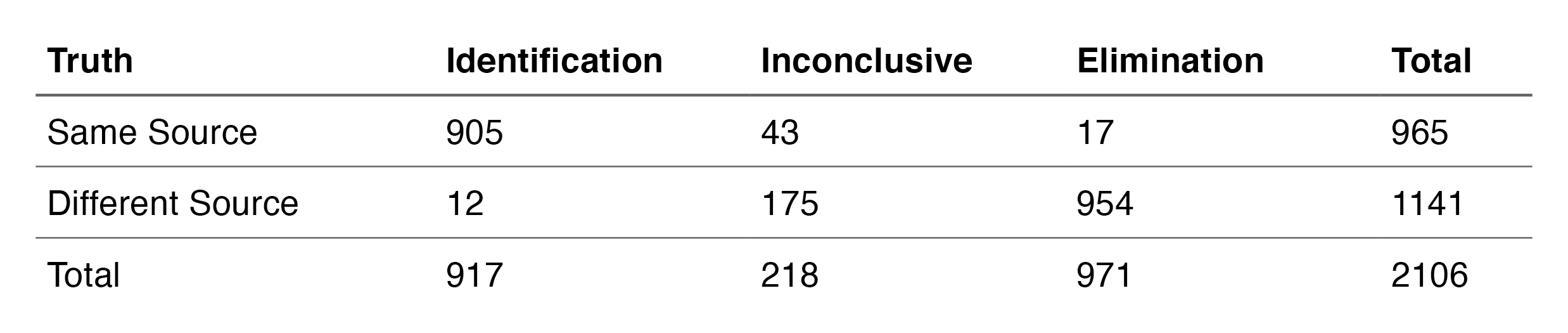
We will use the numbers on the first and second page of this document to illustrate the problem:
Bunch calculates the false-positive error rate as 12/1141 = 1.05% and the false-negative error rate as 17/965 = 1.76%. In both cases, the inconclusive decisions are included in the denominator (total evaluations) and not included in the numerator. This means that when reporting error rates, the inconclusive decisions are never counted as errors—implicitly, they are counted as correct in both cases. While he also reports the sensitivity, specificity and inconclusive rate, none of these terms are labeled as “errors,” which leads to the perception that the error rate for firearms examination is much lower than it should be.
Suppose we exclude inconclusives from the numerator and the denominator. The false-positive error rate using this approach would be 17/923 = 1.84%, and the false-negative error rate would be 12/966 = 1.24%. In both cases, this results in a higher error rate, which demonstrates that the AFTE approach to inconclusives tends to produce misleading results.
The current way errors are reported (when the reporter is being thorough) is to report the percentage of inconclusives in addition to the percentage of false eliminations and false identifications. Unfortunately, when this reporting process is followed, the discrepancy in inconclusive rates between same-source and different-source comparisons is obscured. This hides a significant source of systematic bias.
Are studies representative of casework?
First, we can’t know the answer to this question because we can’t ever know the truth in casework. This is why we have to base everything we know on designed studies because ground truth is known. So, we will never know whether the proportion of e.g., same-source and different-source comparisons in experiments is representative of casework.
What we can know, but do not yet know, is the percentage of decisions that examiners reach that are inconclusive (or identification or eliminations). We are not aware of any studies which report this data for any lab or jurisdiction. As a result, we do not know whether the proportion of inconclusive decisions is similar in casework and designed studies.
What we do know, however, is that the proportion of inconclusives is not constant between studies. In particular, there are much higher inconclusive rates for same-source comparisons in studies conducted in Europe and the U.K. These studies are intended to assess a lab’s skill and are much harder than designed error rate studies in the U.S. So, we know that the design and intent of a study do influence the inconclusive rate. More research in this area is needed.
One possibility for addressing the issue of different examiner behavior in studies versus casework is to implement widespread blind testing—testing in which the examiner is not aware they are participating in a study. The study materials would be set up to mimic evidence and the examiner would write their report as if it was an actual case. This would at least ensure that examiner behavior is similar in the study and the casework. However, this type of study is difficult to design and implement, which explains why it is not commonly done.
In one respect, studies are much harder than casework. In casework, it is much more likely that an elimination can be made on class characteristic mismatches alone. In designed studies, this is often not a scenario that is included. So, designed studies may be harder overall because they often examine consecutively manufactured (and thus more similar) firearms and toolmarks, all of which necessarily have the same class characteristics.
How do you get the predictive probability from a study?
It’s important to note that you can only get the predictive probability from a designed study. This is because you need the proportion of same-source and different-source comparisons as baseline information. These proportions are only known in designed studies and are not at all known in casework. We created a Google worksheet that can help calculate predictive probabilities and the examiner and process error rates. The worksheet is available here.
Why not just exclude inconclusives from all calculations?
One reason is that inconclusive results are still reported in legal settings, but they are not equally likely when examining same-source and different-source evidence, which is informative. Given that an examiner reports an inconclusive result, the source is much more likely to be different than the same. By ignoring inconclusives entirely, we would be throwing out data that is informative. This argument has been made by Biedermann et al., but they did not take the assertion to its obvious conclusion.
What about lab policies that prohibit elimination on individual characteristics?
First, those policies are in direct conflict with the AFTE range of conclusions as published at https://afte.org/about-us/what-is-afte/afte-range-of-conclusions. These guidelines specify “Significant disagreement of discernible class characteristics and/or individual characteristics.” as a reason for an elimination. An interpretation by labs that does not have an elimination based on individual characteristics should be addressed and clarified by AFTE.
Those policies also introduce bias into the examiner’s decision. As can be seen from the rate at which inconclusive results stem from different-source comparisons in case studies, almost all inconclusive results are from different-source comparisons. Some studies controlled for this policy by asking participants to follow the same rules, and even in these studies, the same bias against same-source comparisons being labeled as inconclusive is present. This is true in Bunch and Murphy (conducted at the FBI lab, which has such a policy) and is also true in Baldwin, which was a much larger and more heterogeneous study that requested examiners make eliminations based on individual characteristic mismatches.
A finding of “no identification” could easily be misinterpreted by a non-firearms examiner, such as a juror or attorney, as an elimination.
Under the status quo, an inconclusive can easily be framed as an almost-identification; so, this ambiguity is already present in the system, and we rely on attorneys to frame the issue appropriately for the judge and/or jury. Under our proposal to eliminate inconclusives, we would also have to rely on attorneys to correctly contextualize the information presented by the examiner.
You say that inconclusive results occur more frequently when the conclusion is different-source. Could a conviction occur based on an inconclusive result? Why is this an issue?
Probably not, unless the testimony was something like, “I see a lot of similarities, but not quite enough to establish an identification.” The framing of the inconclusive is important, and at the moment, there is no uniformity in how these results are reported.
The Organization of Scientific Area Committees (OSAC) for Forensic Science, in partnership with the Association of Firearm and Tool Mark Examiners (AFTE), has just released a process map that describes the process that most firearms examiners use when analyzing evidence. The Firearms Process Map provides details about the procedures, methods and decision points most frequently encountered in firearms examination.
From the OSAC press release:
“This map can benefit the firearm discipline by providing a behind-the-scenes perspective into the various components and complexities involved in the firearms examination process. It can also be used to identify best practices, reduce errors, assist in training new examiners and highlight areas where further research or standardization would be beneficial.”
The Firearms Process Map was developed by the National Institute of Standards and Technology (NIST) Forensic Science Research Program through a collaboration with OSAC’s Firearms & Toolmarks Subcommittee and the Association of Firearm and Tool Mark Examiners (AFTE).