The way in which jurors perceive reports of forensic evidence is of critical importance, especially in cases of forensic identification evidence that require examiners to compare items and assess whether they originate from a common source. The current study discusses methods for studying group differences among mock jurors and illustrates them using a reanalysis of data regarding lay perceptions of forensic science evidence. Conventional approaches that consider subpopulations defined a priori are compared with mixture models that infer group structure from the data, allowing detection of subgroups that cohere in unexpected ways. Mixture models allow researchers to determine whether a population comprises subpopulations that respond to evidence differently and then to consider how those subpopulations might be characterized. The reanalysis reported here shows that mixture models can enhance understanding of lay perceptions of an important type of forensic science evidence (DNA and fingerprint comparisons), providing insight into how the perceived strength of that evidence varies as a function of the language forensic experts use to describe their findings. This novel application of mixture models illustrates how such models can be used, more generally, to explore the importance of juror characteristics in jury decision making.
The present study examined whether a defense rebuttal expert can effectively educate jurors on the risk that the prosecution’s fingerprint expert made an error. Using a sample of 1716 jury-eligible adults, we examined the impact of three types of rebuttal testimony in a mock trial: (a) a methodological rebuttal explaining the general risk of error in the fingerprint-comparison process; (b) a new-evidence rebuttal concluding the latent fingerprint recovered in this case was not suitable for use in a comparison; and (c) a new-evidence rebuttal excluding the defendant as the source of the latent fingerprint. All three rebuttals significantly altered perceptions of the prosecution’s fingerprint evidence, but new-evidence rebuttals proved most effective. The effectiveness of the rebuttals depended, however, on whether jurors were more concerned about false acquittals or false convictions.
Recognition of overlapping objects is required in many applications in the field of computer vision. Examples include cell segmentation, bubble detection and bloodstain pattern analysis. This paper presents a method to identify overlapping objects by approximating them with ellipses. The method is intended to be applied to complex-shaped regions which are believed to be composed of one or more overlapping objects. The method has two primary steps. First, a pool of candidate ellipses are generated by applying the Euclidean distance transform on a compressed image and the pool is filtered by an overlaying method. Second, the concave points on the contour of the region of interest are extracted by polygon approximation to divide the contour into segments. Then, the optimal ellipses are selected from among the candidates by choosing a minimal subset that best fits the identified segments. We propose the use of the adjusted Rand index, commonly applied in clustering, to compare the fitting result with ground truth. Through a set of computational and optimization efficiencies, we are able to apply our approach in complex images comprised of a number of overlapped regions. Experimental results on a synthetic data set, two types of cell images and bloodstain patterns show superior accuracy and flexibility of our method in ellipse recognition, relative to other methods.
On the heels of the recently reported Massachusetts drug lab scandal, Brandon L. Garrett and Peter Stout published an article on Slate.com calling for a critical look at redirecting funding to crime labs.
Amid a national conversation over where to best allocate law enforcement dollars, we call for a critical look at redirecting funding to other agencies in the criminal justice system that are often forgotten and overlooked—namely, crime labs. Critically, those labs must have sound quality control and adequate resources and must be independent of law enforcement.
They highlight two cases where people were convicted and sentenced to prison based on either evidence from a crime scene contaminated by poorly trained police or flawed testimony by a police examiner. Garrett and Stout noted that these are not isolated cases:
The database Convicting the Innocent, which tracks the role forensics played in cases of people exonerated by DNA, shows that more than half of those 300-plus exonerees, who spent an average of 14 years in prison, were convicted based on flawed forensics.
They concluded their article by stating:
If the criminal justice system is to work properly, it needs access to science that is best supported in well-funded, independent, and scientist-led and -driven crime laboratories. Sound science and justice both demand accurate evidence, which means getting forensics right. And getting forensics right demands reform accountability for our labs, independence, and adequate funding.
Garrett is co-director of the Center for Statistics and Applications in Forensic Evidence (CSAFE) and the L. Neil Williams professor of law at Duke University, where he directs the Wilson Center for Science and Justice. Stout is the CEO and president of the Houston Forensic Science Center. He is also a member of the CSAFE Strategic Advisory Board.
Discover how CSAFE is building strong scientific foundations that enhance forensic science and technology practices. Check out CSAFE’s research areas at https://forensicstats.org/our-research/.
Over the past decade, with increasing scientific scrutiny on forensic reporting practices, there have been several efforts to introduce statistical thinking and probabilistic reasoning into forensic practice. These efforts have been met with mixed reactions—a common one being scepticism, or downright hostility, towards this objective. For probabilistic reasoning to be adopted in forensic practice, more than statistical knowledge will be necessary. Social scientific knowledge will be critical to effectively understand the sources of concern and barriers to implementation. This study reports the findings of a survey of forensic fingerprint examiners about reporting practices across the discipline and practitioners’ attitudes and characterizations of probabilistic reporting. Overall, despite its adoption by a small number of practitioners, community-wide adoption of probabilistic reporting in the friction ridge discipline faces challenges. We found that almost no respondents currently report probabilistically. Perhaps more surprisingly, most respondents who claimed to report probabilistically, in fact, do not. Furthermore, we found that two-thirds of respondents perceive probabilistic reporting as ‘inappropriate’—their most common concern being that defence attorneys would take advantage of uncertainty or that probabilistic reports would mislead, or be misunderstood by, other criminal justice system actors. If probabilistic reporting is to be adopted, much work is still needed to better educate practitioners on the importance and utility of probabilistic reasoning in order to facilitate a path towards improved reporting practices.
In criminal cases, forensic science reports and expert testimony play an increasingly important role in adjudication. More states now follow a federal reliability standard, which calls upon judges to assess the reliability and validity of scientific evidence. Little is known about how judges view their own background in forensic scientific evidence, and what types of specialized training they receive on it. In this study, we surveyed 164 judges from 39 different U.S. states, who attended past trainings at the National Judicial College. We asked these judges about their background in forensic science, their views concerning the reliability of common forensic disciplines, and their needs to better evaluate forensic science evidence. We discovered that judges held views regarding the scientific support for different forensic science disciplines that were fairly consistent with available literature; their error rate estimates were more supported by research than many estimates by laypersons, who often assume forensic methods are nearly infallible. We did not find any association between how judges rate forensic reliability and prior training. We did, however, find that training corresponded with judges’ views that they should, and do in fact, take on a more active gatekeeping role regarding forensics. Regarding the tools judges need to vet forensic experts and properly evaluate forensic science evidence, they reported having very different backgrounds in relevant scientific concepts and having forensic science education needs. Judges reported needs in accessing better material concerning reliability of forensic science methods. These results support new efforts to expand scientific evidence education in the judiciary.
Scholarship on the latent print comparison process has expanded in recent years, responsive to the call for rigorous research by scholarly groups (e.g., National Academy of Sciences, 2009; President’s Council of Advisors on Science and Technology, 2016). Important to the task of ultimately improving accuracy, consistency, and efficiency in the field is understanding different workflows and case outcomes. The current study describes the casework completed by a latent print unit in a large laboratory during one calendar year (2018), including a unique workflow that involves Preliminary AFIS Associations reported out as investigative leads. Approximately 45% of all examined prints were deemed to be of sufficient quality to enter into AFIS, and 22% of AFIS entries resulted in potential identifications. But examiner conclusions and AFIS outcomes (across three AFIS databases) varied according to case details, print source, and AFIS database. Moreover, examiners differed in case processing, sufficiency determinations, and AFIS conclusions. Results are discussed with respect to implications for future research (e.g., comparing these data to case processing data for other laboratories) and ultimately improving the practice of latent print examination.
On Feb. 10, the Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted the webinar, Treatment of Inconclusive Results in Error Rates of Firearms Studies. It was presented by Heike Hofmann, a professor and Kingland Faculty Fellow at Iowa State University, Susan VanderPlas, a research assistant professor at the University of Nebraska, Lincoln; and Alicia Carriquiry, CSAFE director and Distinguished Professor and President’s Chair in Statistics at Iowa State.
In the webinar, Hofmann, VanderPlas and Carriquiry revisited several Black Box studies that attempted to estimate the error rates of firearms examiners, investigating their treatment of inconclusive results. During the Q&A portion of the webinar, the presenters ran out of time to answer everyone’s questions. Hofmann, VanderPlas and Carriquiry have combined and rephrased the questions to cover the essential topics that were covered in Q&A. Their answers are below.
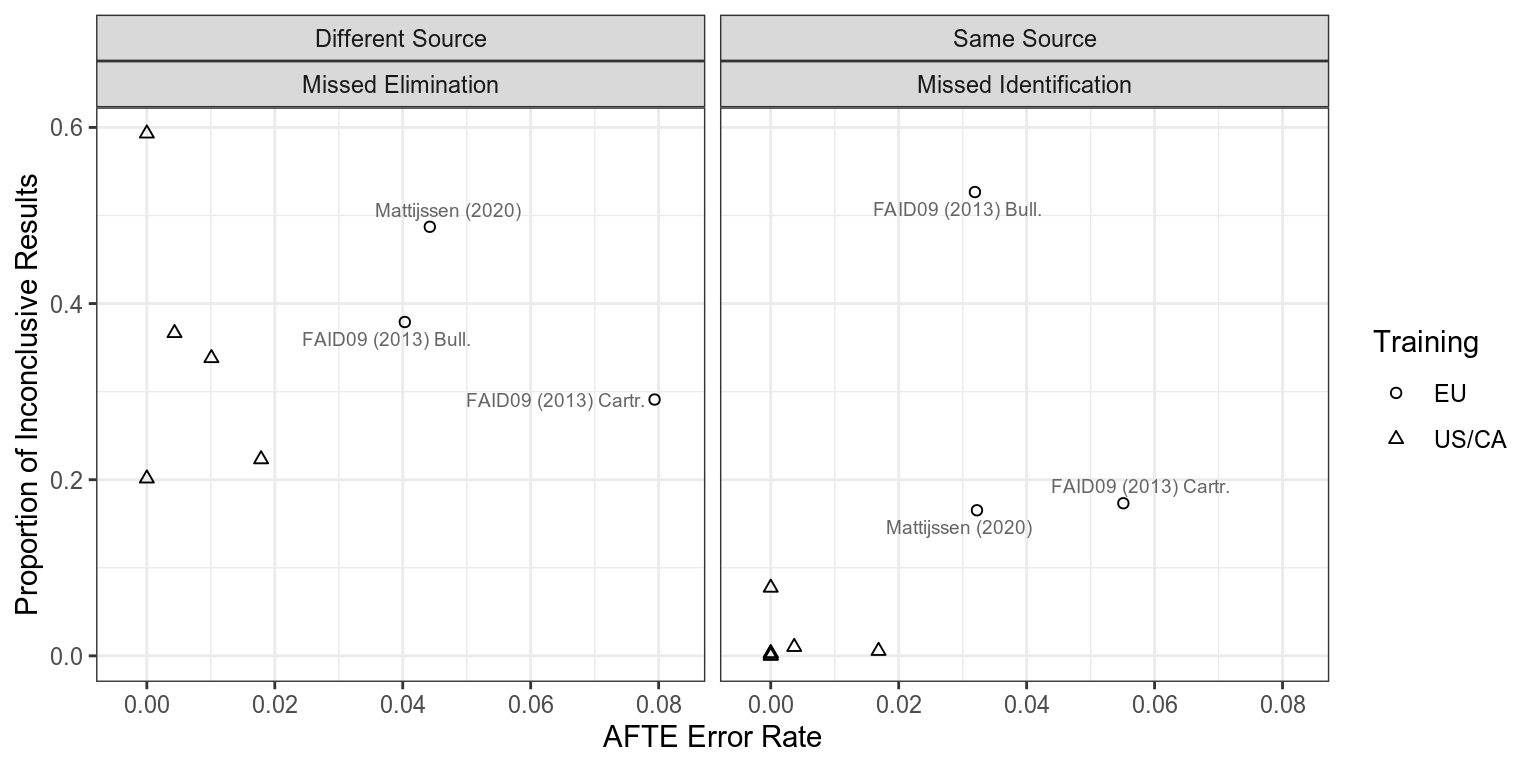
Is the inconclusive rate related to the study difficulty?
There is no doubt that we looked at several studies with different difficulty, as well as different study designs, comparison methods and examiner populations. When we examine the AFTE error rate (so only eliminations of same-source comparisons or identifications of different-source comparisons), compared to the rate of inconclusive decisions, we see that there is a clear difference between the studies conducted in Europe/U.K. and studies conducted in North America.
The EU/U.K. studies were conducted to assess lab proficiency (for the most part), and consequently, they seem to have been constructed to be able to distinguish good laboratories from excellent laboratories. So, they do include harder comparisons. The more notable result isn’t the difference in the error rates, which is relatively small; but rather, the largest difference is in the proportion of inconclusives in different-source and same-source comparisons. In the EU/U.K. studies, the proportion of inconclusives is similar for both types of comparisons. In the U.S./CA studies, the proportion of inconclusives for same-source comparisons is a fraction of the proportion of inconclusives for different-source comparisons.
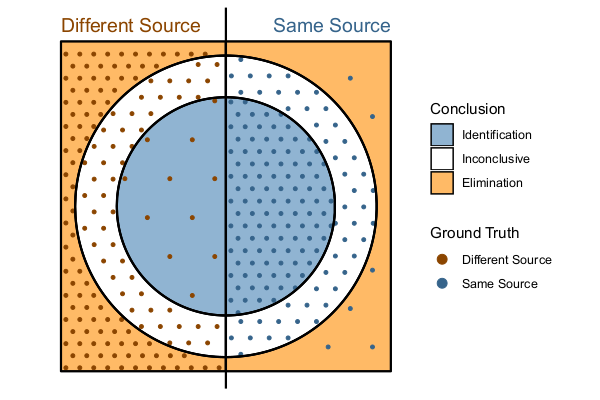
If we think about what the study results should ideally look like, we might come up with something like this:
Results of an ideal study.
In this figure, there are many different-source eliminations and same-source identifications. There are equally many same-source and different-source inconclusives, and in both cases, erroneous decisions (same-source exclusions and different-source identifications) are relatively rare. The proportion of inconclusives might be greater or smaller depending on the study difficulty or examiner experience levels, and the proportion of different-source and same-source identifications may be expected to vary somewhat depending on the study design (thus, the line down the center might shift to the left or the right). Ultimately, the entire study can be represented by this type of graphic showing the density of points in each region.
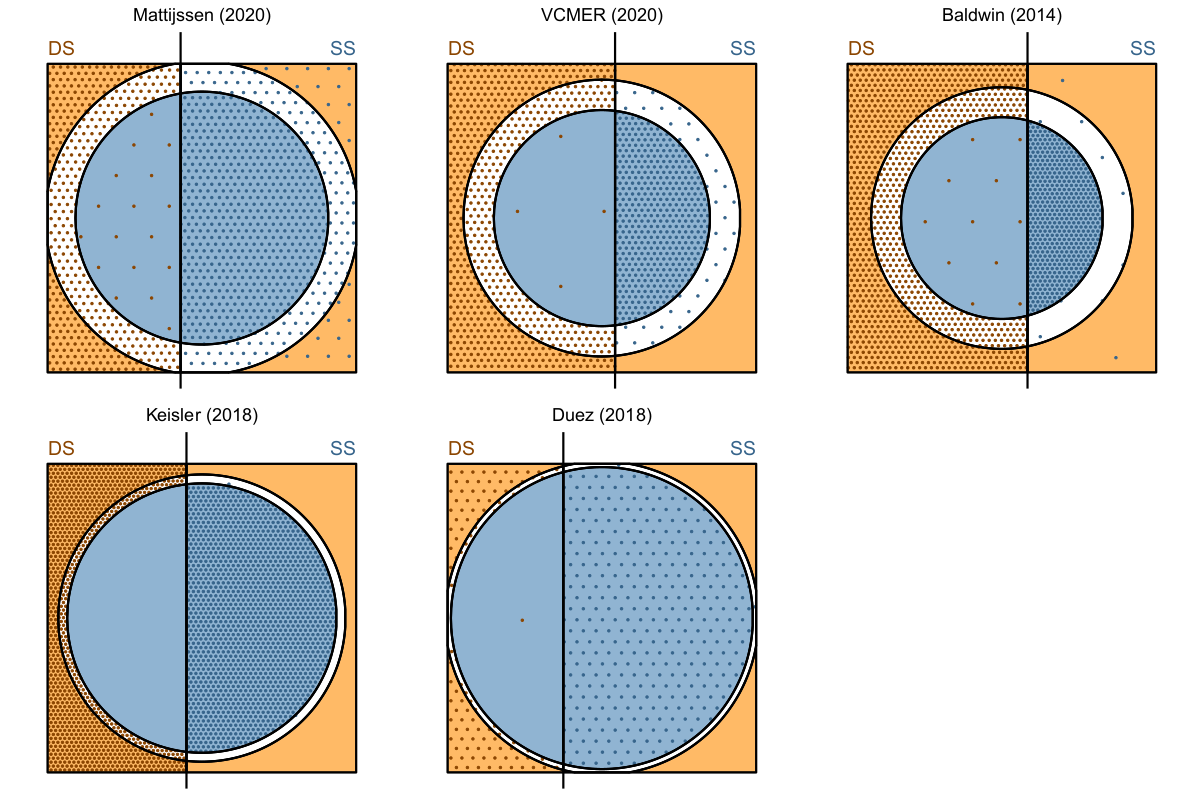
Results visualized for several different studies.
When we look at the results of several studies, we see that none of them conform precisely to this expectation. As expected, the proportion of same-source and different-source decisions vary across the studies (Baldwin includes more different-source comparisons, while Mattijssen includes more same-source comparisons), and the proportion of inconclusive results differs, with more inconclusives in the top three studies relative to Keisler and Duez. However, the most notable difference is that the proportion of inconclusive results for different-source comparisons is much higher than the proportion of inconclusive results for same-source comparisons across studies. This discrepancy is less noticeable but still present for Mattijssen (2020), which was primarily completed by EU-trained examiners. In Baldwin, Keisler and Duez, the proportion of different-source comparisons judged inconclusive makes the inconclusive category appear as an extension of the elimination—the dots have approximately the same density, and the corresponding same-source inconclusive point density is so much lower that it is nearly unnoticeable in comparison.
The real story here seems to be that while more difficult studies do seem to have slightly higher error rates (which is expected), the training, location and lab policies that influence examiner evaluations have a real impact on the proportion of inconclusive decisions which are reached. The EU/U.K. studies provide some evidence for the fact that the bias in inconclusive error rates demonstrated in our paper is a solvable problem.
Examiners often report a final answer of “inconclusive,” and this is correct according to the AFTE standard. Should inconclusives be allowed as a final answer?
From a statistical perspective, there is a mismatch between the state of reality (same source or different source) and the decision categories. This causes some difficulty when calculating error rates. We proposed multiple ways to handle this situation: using predictive probabilities, distinguishing between process error and examiner error or reframing the decision to one of identification or not-identification. Any of these options provide a much clearer interpretation of what an error is and its relevance in legal settings.
In practice, we recognize that not all evidence collected will be suitable to conclude identification or elimination due to several factors. These factors are often considered “process errors,” and examiners are trained to account for these errors and reach an inconclusive decision. We agree that this is a reasonable decision to make based on the circumstances. The issue with inconclusive decisions arises when results are presented in court, all of the errors which could contribute to the process are relevant. Thus, it is important to report the process error and the examiner-based (AFTE) error.
In some cases, however, the examiner may have noted many differences at the individual level but be uncomfortable making an elimination (in some cases, due to lab policies prohibiting elimination based on individual characteristics). That there is hesitation to make this decision is an example of the bias we have demonstrated: when there is some evidence of similarity, examiners appear to be more willing to “bet” on an identification than on an elimination based on a similar amount of dissimilarity. This higher burden of proof is an issue that has consequences for the overall error rates reported from these studies as well as the actual errors that may occur in the legal system itself.
How should courts prevent misused error rates?
The critical component to preventing misuse of error rates is to understand how error rates should be interpreted. Currently, most error rates reported include inconclusives in the denominator but not in the numerator. As we have demonstrated in our paper and this Q&A, this approach leads to error rates that are misleadingly low for the overall identification process and not actionable in a legal situation. Instead, courts should insist on predictive error rates: given the examiner’s decision, what is the probability that it resulted from a same-source or different-source comparison? These probabilities do not rely on inconclusives in the calculations and are relevant to the specific result presented by the examiner in the trial at hand.
What error rate should we use when?
The error rate we want is entirely dependent on the intended use:
In court, we should use predictive probabilities because they provide specific information which is relevant to the individual case under consideration.
In evaluating examiners, the AFTE error rates, which do not include inconclusives, may be much more useful—they identify examiner errors rather than errors that arise due to situations in which the evidence is recorded and collected. For labs, it is of eminent concern that all of their examiners are adequately trained.
It’s very important to consider the context that an error rate or probability is used and to calculate the error rate which is most appropriate for that context.
Why do you claim AFTE treats inconclusives as correct results?
In the AFTE response to the PCAST report, the response specifically discusses false identifications and false eliminations with no discussion of inconclusive results. Given that this is a foundational dispute, the way that AFTE presents these quantities in other literature is relevant, which is why we will demonstrate the problem with data pulled from AFTE’s resources for error rate calculations.
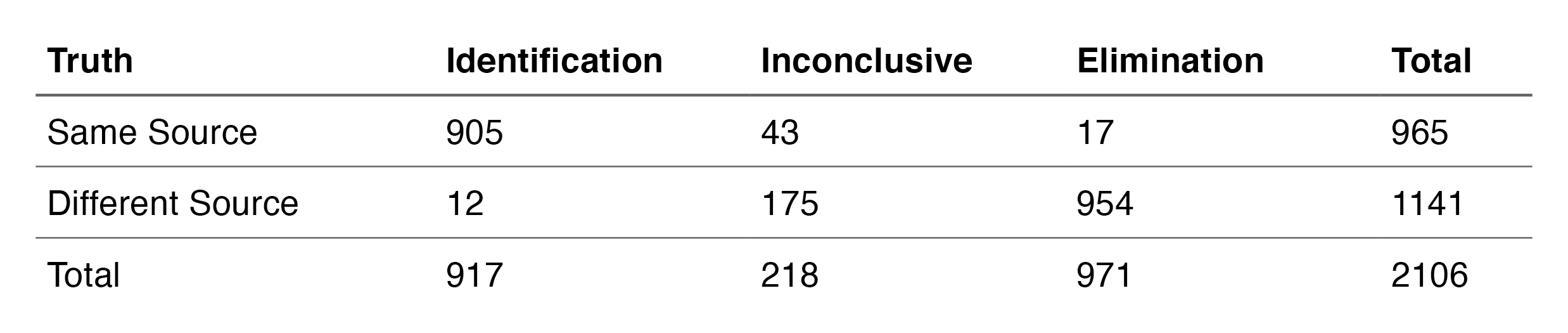
We will use the numbers on the first and second page of this document to illustrate the problem:
Bunch calculates the false-positive error rate as 12/1141 = 1.05% and the false-negative error rate as 17/965 = 1.76%. In both cases, the inconclusive decisions are included in the denominator (total evaluations) and not included in the numerator. This means that when reporting error rates, the inconclusive decisions are never counted as errors—implicitly, they are counted as correct in both cases. While he also reports the sensitivity, specificity and inconclusive rate, none of these terms are labeled as “errors,” which leads to the perception that the error rate for firearms examination is much lower than it should be.
Suppose we exclude inconclusives from the numerator and the denominator. The false-positive error rate using this approach would be 17/923 = 1.84%, and the false-negative error rate would be 12/966 = 1.24%. In both cases, this results in a higher error rate, which demonstrates that the AFTE approach to inconclusives tends to produce misleading results.
The current way errors are reported (when the reporter is being thorough) is to report the percentage of inconclusives in addition to the percentage of false eliminations and false identifications. Unfortunately, when this reporting process is followed, the discrepancy in inconclusive rates between same-source and different-source comparisons is obscured. This hides a significant source of systematic bias.
Are studies representative of casework?
First, we can’t know the answer to this question because we can’t ever know the truth in casework. This is why we have to base everything we know on designed studies because ground truth is known. So, we will never know whether the proportion of e.g., same-source and different-source comparisons in experiments is representative of casework.
What we can know, but do not yet know, is the percentage of decisions that examiners reach that are inconclusive (or identification or eliminations). We are not aware of any studies which report this data for any lab or jurisdiction. As a result, we do not know whether the proportion of inconclusive decisions is similar in casework and designed studies.
What we do know, however, is that the proportion of inconclusives is not constant between studies. In particular, there are much higher inconclusive rates for same-source comparisons in studies conducted in Europe and the U.K. These studies are intended to assess a lab’s skill and are much harder than designed error rate studies in the U.S. So, we know that the design and intent of a study do influence the inconclusive rate. More research in this area is needed.
One possibility for addressing the issue of different examiner behavior in studies versus casework is to implement widespread blind testing—testing in which the examiner is not aware they are participating in a study. The study materials would be set up to mimic evidence and the examiner would write their report as if it was an actual case. This would at least ensure that examiner behavior is similar in the study and the casework. However, this type of study is difficult to design and implement, which explains why it is not commonly done.
In one respect, studies are much harder than casework. In casework, it is much more likely that an elimination can be made on class characteristic mismatches alone. In designed studies, this is often not a scenario that is included. So, designed studies may be harder overall because they often examine consecutively manufactured (and thus more similar) firearms and toolmarks, all of which necessarily have the same class characteristics.
How do you get the predictive probability from a study?
It’s important to note that you can only get the predictive probability from a designed study. This is because you need the proportion of same-source and different-source comparisons as baseline information. These proportions are only known in designed studies and are not at all known in casework. We created a Google worksheet that can help calculate predictive probabilities and the examiner and process error rates. The worksheet is available here.
Why not just exclude inconclusives from all calculations?
One reason is that inconclusive results are still reported in legal settings, but they are not equally likely when examining same-source and different-source evidence, which is informative. Given that an examiner reports an inconclusive result, the source is much more likely to be different than the same. By ignoring inconclusives entirely, we would be throwing out data that is informative. This argument has been made by Biedermann et al., but they did not take the assertion to its obvious conclusion.
What about lab policies that prohibit elimination on individual characteristics?
First, those policies are in direct conflict with the AFTE range of conclusions as published at https://afte.org/about-us/what-is-afte/afte-range-of-conclusions. These guidelines specify “Significant disagreement of discernible class characteristics and/or individual characteristics.” as a reason for an elimination. An interpretation by labs that does not have an elimination based on individual characteristics should be addressed and clarified by AFTE.
Those policies also introduce bias into the examiner’s decision. As can be seen from the rate at which inconclusive results stem from different-source comparisons in case studies, almost all inconclusive results are from different-source comparisons. Some studies controlled for this policy by asking participants to follow the same rules, and even in these studies, the same bias against same-source comparisons being labeled as inconclusive is present. This is true in Bunch and Murphy (conducted at the FBI lab, which has such a policy) and is also true in Baldwin, which was a much larger and more heterogeneous study that requested examiners make eliminations based on individual characteristic mismatches.
A finding of “no identification” could easily be misinterpreted by a non-firearms examiner, such as a juror or attorney, as an elimination.
Under the status quo, an inconclusive can easily be framed as an almost-identification; so, this ambiguity is already present in the system, and we rely on attorneys to frame the issue appropriately for the judge and/or jury. Under our proposal to eliminate inconclusives, we would also have to rely on attorneys to correctly contextualize the information presented by the examiner.
You say that inconclusive results occur more frequently when the conclusion is different-source. Could a conviction occur based on an inconclusive result? Why is this an issue?
Probably not, unless the testimony was something like, “I see a lot of similarities, but not quite enough to establish an identification.” The framing of the inconclusive is important, and at the moment, there is no uniformity in how these results are reported.
Handwritten documents can be characterized by their content or by the shape of the written characters. We focus on the problem of comparing a person’s handwriting to a document of unknown provenance using the shape of the writing, as is done in forensic applications. To do so, we first propose a method for processing scanned handwritten documents to decompose the writing into small graphical structures, often corresponding to letters. We then introduce a measure of distance between two such structures that is inspired by the graph edit distance, and a measure of center for a collection of the graphs. These measurements are the basis for an outlier tolerant K‐means algorithm to cluster the graphs based on structural attributes, thus creating a template for sorting new documents. Finally, we present a Bayesian hierarchical model to capture the propensity of a writer for producing graphs that are assigned to certain clusters. We illustrate the methods using documents from the Computer Vision Lab dataset. We show results of the identification task under the cluster assignments and compare to the same modeling, but with a less flexible grouping method that is not tolerant of incidental strokes or outliers.
Kori Khan Assistant Professor Department of Statistics, Iowa State University
We are currently in an era where machine learning and algorithms offer novel approaches to solving problems both new and old. Algorithmic approaches are swiftly being adopted for a range of issues: from making hiring decisions for private companies to sentencing criminal defendants. At the same time, researchers and legislators are struggling with how to evaluate and regulate such approaches.
The regulation of algorithmic output becomes simultaneously more complex and pressing in the context of the American criminal justice system. U.S. courts are regularly admitting evidence generated from algorithms in criminal cases. This is perhaps unsurprising given the permissive standards for admission of evidence in American criminal trials. Once admitted, however, the algorithms used to generate the evidence—which are often proprietary or designed for litigation—present a unique challenge. Attorneys and judges face questions about how to evaluate algorithmic output when a person’s liberty hangs in the balance. Devising answers to these questions inevitably involves delving into an increasingly contentious issue—access to the source code.
In criminal courts across the country, it appears most criminal defendants have been denied access to the source code of algorithms used to produce evidence against them. I write, “it appears,” because here, like in most areas of the law, empirical research into legal trends is limited to case studies or observations about cases that have drawn media attention. For these cases, the reasons for denying a criminal defendant access to the source code have not been consistent. Some decisions have pointed out that the prosecution does not own the source code, and therefore is not required to produce it. Others implicitly acknowledge that the prosecution could be required to produce the source code and instead find that the defendant has not shown a need for access to the source code. It is worth emphasizing that these decisions have not found that the defendant does not need access to source code; but rather, that the defendant has failed to sufficiently establish that need. The underlying message in many of these decisions, whether implicit or explicit, is that there will be cases, perhaps quite similar to the case being considered, where a defendant will require access to source code to mount an effective defense. The question of how to handle access to the code in such cases does not have a clear answer.
Legal scholars are scrambling to provide guidance. Loosely speaking, proposals can be categorized into two groups: those that rely on existing legal frameworks and those that suggest a new framework might be necessary. For the former category, the heart of the issue is the tension between the intellectual property rights of the algorithm’s producer and the defendant’s constitutional rights. On the one hand, the producers of algorithms often have a commercial interest in ensuring that competitors do not have access to the source code. On the other hand, criminal defendants have the right to question the weight of the evidence presented in court.
There is a range of opinions on how to balance these competing interests. These opinions run along a spectrum of always allowing defendants access to source code to rarely allowing defendants access to the code. However, most fall somewhere in the middle. Some have suggested “front-end” measures in which lawmakers establish protocols to ensure the accuracy of algorithmic output before their use in criminal courts. These measures might include an escrowing of the source code, similar to how some states have handled voting technology. Within the courtroom, suggestions for protecting the producers of code include utilizing traditional measures, such as the protective orders commonly used in trade secret suits. Other scholars have proposed a defendant might not always need access to source code. For example, some suggest that if the producer of the algorithm is willing to run tests constructed by the defense team, this may be sufficient in many cases. Most of these suggestions make two key assumptions: 1) either legislators or defense attorneys should be able to devise standards to identify the cases for which access to source code is necessary to evaluate an algorithm and 2) legislators or defense attorneys can devise these standards without access to the source code themselves.
These assumptions require legislators and defense attorneys to answer questions that the scientific community itself cannot answer. Outside of the legal setting, researchers are faced with a similar problem: how can we evaluate scientific findings that rely on computational research? For the scientific community, the answer for the moment is that we are not sure. There is evidence that the traditional methods of peer review are inadequate. In response, academic journals and institutes have begun to require that researchers share their source code and any relevant data. This is increasingly viewed as a minimal standard to begin to evaluate computational research, including algorithmic approaches. However, just as within the legal community, the scientific community has no clear answers for how to handle privacy or proprietary interests in the evaluation process.
In the past, forensic science methods used in criminal trials have largely been developed and evaluated outside the purview of the larger scientific community, often on a case-by-case basis. As both the legal and scientific communities face the challenge of regulating algorithms, there is an opportunity to expand existing interdisciplinary forums and create new ones.