


A common question in forensic analysis is whether two observed data sets originate from the same source or from different sources. Statistical approaches to addressing this question have been widely adopted within the forensics community, particularly for DNA evidence, providing forensic investigators with tools that allow them to make robust inferences from limited and noisy data. For other types of evidence, such as fingerprints, shoeprints, bullet casing impressions and glass fragments, the development of quantitative methodologies is more challenging. In particular, there are significant challenges in developing realistic statistical models, both for capturing the process by which the evidential data is produced and for modeling the inherent variability of such data from a relevant population.
In this context, the increased prevalence of digital evidence presents both opportunities and challenges from a statistical perspective. Digital evidence is typically defined as evidence obtained from a digital device, such as a mobile phone or computer. As the use of digital devices has increased, so too has the amount of user-generated event data collected by these devices. However, current research in digital forensics often focuses on addressing issues related to information extraction and reconstruction from devices and not on quantifying the strength of evidence as it relates to questions of source.
This dissertation begins with a survey of techniques for quantifying the strength of evidence (the likelihood ratio, score-based likelihood ratio and coincidental match probability) and evaluating their performance. The evidence evaluation techniques are then adapted to digital evidence. First, the application of statistical approaches to same-source forensic questions for spatial event data, such as determining the likelihood that two sets of observed GPS locations were generated by the same individual, is investigated. The methods are applied to two geolocated event data sets obtained from social networks. Next, techniques are developed for quantifying the degree of association between pairs of discrete event time series, including a novel resampling technique when population data is not available. The methods are applied to simulated data and two real-world data sets consisting of logs of computer activity and achieve accurate results across all data sets. The dissertation concludes with suggestions for future work.




Objectivity and accuracy are the pinnacle of forensic science. Yet everyone can agree: humans make errors — but to what degree when it comes to digital forensic evidence-gathering and analysis?
The National Institute of Standards and Technology (NIST) is launching the first “blackbox” research study to quantify the accuracy of computer and mobile phone forensics and answer this question.
Digital evidence provides an additional layer of potential human error, especially taking into consideration rapidly evolving technologies, and situations when key evidence must be identified and extracted from large volumes of digital data. It is for these reasons that CSAFE too has is working on a mobile app analysis tool EVIHUNTER.
On a broader scale, this NIST study acts as an answer to the 2009 National Academy of Sciences report: Strengthening Forensic Science in the United States: A Path Forward, which calls for blackbox studies to measure reliability of forensic methods that involve human judgement.
Digital evidence, though grounded in technology, certainly relies on the human element. By participating in the NIST study, digital forensic practitioners can help strengthen the future of forensic science by providing a foundation of quantitative probability that can be used by courts and jurors to weigh the validity of presented digital evidence and analysis — as well as inform future studies needed in this realm. Digital forensic experts can answer a question paramount to fulfilling their own goals and missions in their positions: Are our industry sector’s methods accurate and reliable?
The Study Details
Blackbox studies are unique in their anonymity. They assess the reliability and accuracy (right or wrong) of human judgement methods only, without concern for how experts reached their answer. Therefore, the study will not judge individuals and their performance but rather will be aimed to measure the performance of the digital forensics community as a whole.
The study will be conducted online — and enrollment is now open and the test is available for approximately three months.
Digital forensic experts who volunteer for the study will be provided a download of simulated evidence from the NIST website, in the form of one virtual mobile phone and one virtual computer. In roughly a two-hour time commitment, participants will be asked to examine simulated digital evidence and answer a series of questions similar to those that would be expected in a real criminal investigation. Participants will use forensic software tools of their choosing to analyze the forensic images.
Who Can Participate
All public and private sector digital examiners who conduct hard drive or mobile phone examinations as part of their official duties are encouraged to volunteer and participate in this study.
No one individual’s performance or laboratory will be calculated. Rather, NIST will publish anonymized and comprehensive results of the overall performance of the digital forensic expert community and different sectors within that community.
To learn more or to enroll in this vital study to advancing digital forensics forward, visit NIST Blackbox Study for Digital Examiners and follow the simple steps to get started.
Digital image forensics is a field encompassing camera identication, forgery detection and steganalysis. Statistical modeling and machine learning have been successfully applied in the academic community of this maturing field. Still, large gaps exist between academic results and applications used by practicing forensic analysts, especially when the target samples are drawn from a different population than the data in a reference database.
This thesis contains four published papers aiming at narrowing this gap in three different fields: mobile stego app detection, digital image steganalysis and camera identification. It is the first work to explore a way of extending the academic methods to real world images created by apps. New ideas and methods are developed for target images with very rich flexibility in the embedding rates, embedding algorithms, exposure settings and camera sources. The experimental results proved that the proposed methods work very well, even for the devices which are not included in the reference database.
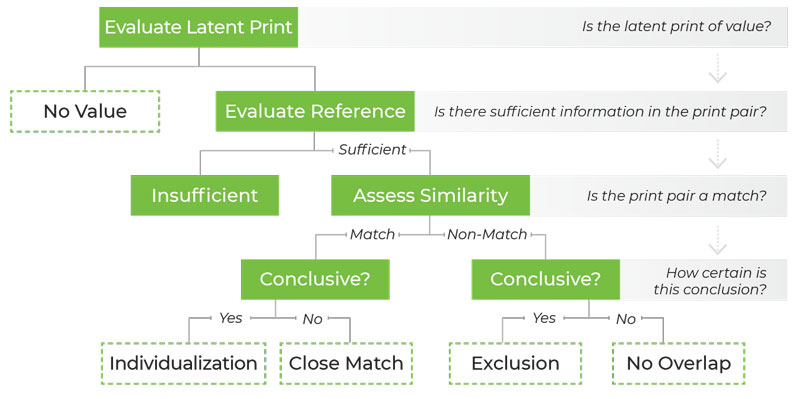
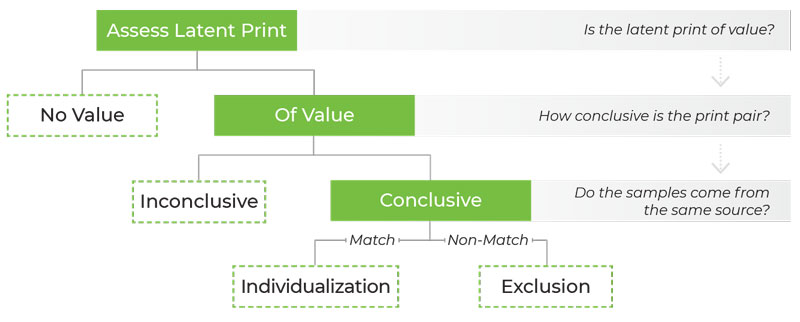

The decade since the publication of the 2009 National Research Council report on forensic science has seen the increasing use of a new word to describe forensic results. What were once called “facts,” “determinations,” “conclusions,” or “opinions,” are increasingly described as “decisions.” Prior to 2009, however, the term “decision” was rarely used to describe forensic results. Lay audiences, such as lawyers, might be forgiven for perceiving this as a surprising turn. In its plain English meaning, a “decision” would seem to be a strange word choice to describe the outcome of a scientific analysis, given its connotation of choice and preference. In this Article, we trace the recent history of the term “decision” in forensic analysis. We simply and clearly explain the scientific fields of “decision theory” and “decision analysis” and their application to forensic science. We then analyze the Department of Justice (DOJ) Uniform Language for Testimony and Reporting (ULTR) documents that use the term. We argue that these documents fail to articulate coherent frameworks for reporting forensic results. The Article identifies what we perceive to be some key stumbling blocks to developing such frameworks. These include a reluctance to observe decision theory principles, a reluctance to cohere with sound probabilistic principles, and a reluctance to conform to particular logical concepts associated with these theories, such as proper scoring rules. The Article elucidates each of these perceived stumbling blocks and proposes a way to move forward to more defensible reporting frameworks. Finally, we explain what the use of the term “decision” could accomplish for forensic science and what an appropriate deployment of the term would require.

We propose a novel method to quantify the similarity between an impression (Q) from an unknown source and a test impression (K) from a known source. Using the property of geometrical congruence in the impressions, the degree of correspondence is quantified using ideas from graph theory and maximum clique (MC). The algorithm uses the x and y coordinates of the edges in the images as the data. We focus on local areas in Q and the corresponding regions in K and extract features for comparison. Using pairs of images with known origin, we train a random forest to classify pairs into mates and non-mates. We collected impressions from 60 pairs of shoes of the same brand and model, worn over six months. Using a different set of very similar shoes, we evaluated the performance of the algorithm in terms of the accuracy with which it correctly classified images into source classes. Using classification error rates and ROC curves, we compare the proposed method to other algorithms in the literature and show that for these data, our method shows good classification performance relative to other methods. The algorithm can be implemented with the R package shoeprintr.
We propose a novel method to quantify the similarity between an impression (Q) from an unknown source and a test impression (K) from a known source. Using the property of geometrical congruence in the impressions, the degree of correspondence is quantified using ideas from graph theory and maximum clique (MC). The algorithm uses the x and y coordinates of the edges in the images as the data. We focus on local areas in Q and the corresponding regions in K and extract features for comparison. Using pairs of images with known origin, we train a random forest to classify pairs into mates and non-mates. We collected impressions from 60 pairs of shoes of the same brand and model, worn over six months. Using a different set of very similar shoes, we evaluated the performance of the algorithm in terms of the accuracy with which it correctly classified images into source classes. Using classification error rates and ROC curves, we compare the proposed method to other algorithms in the literature and show that for these data, our method shows good classification performance relative to other methods. The algorithm can be implemented with the R package shoeprintr.





