On June 23, the Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted the webinar, Blind Testing in Firearms Examination: Preliminary Results, Benefits, Limitations, and Future Directions. It was presented by Maddisen Neuman, a Quality / Research Associate at the Houston Forensic Science Center (HSFC).
In the webinar, Neuman shares the methodology for HSFC’s blind proficiency testing program, as well as results from a recent study of 51 blind cases submitted to examiners between 2015 and 2021.
If you did not attend the webinar live, the recording is available at https://forensicstats.org/blog/portfolio/blind-testing-in-firearms-examination/
If an examiner knows they are being tested, results from a study can be skewed, so several governing bodies in the forensic science community recommend conducting blind proficiency tests to achieve more precise results. Researchers can do this by inserting test samples into the flow of casework so examiners do not know that they are being tested.
HSFC implemented its blind quality control program in 2015 and creates mock case evidence in house, with the goal of submitting test material at a rate of five percent of each section’s output from the year before.
The biggest advantage is having a ground truth against which to compare examination results, which is not known in normal casework. Additionally, because examiners aren’t aware which cases are test cases, they perform the work as they would for a normal case. This allows researchers to observe the entire examination process, from evidence submission to the reporting of results.
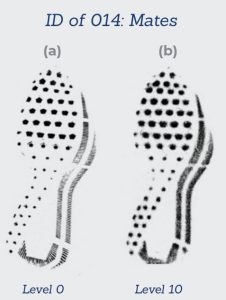
Blind cases mimic routine evidence and cases in order to appear authentic. The firearm used to create the fired evidence may or may not be submitted as an additional piece of evidence. Though HFSC has a large reference collection, blind tests are not created from this library as the examiners are likely to recognize the evidence. Some fired evidence is created using personal firearms from employees of HFSC.
HFSC researchers have also developed a partnership with the Houston Police Department (HPD), and regularly use firearms the property room division has slated for destruction to create mock evidence for blind testing. These firearms are often representative of the types of firearms seen frequently in casework.
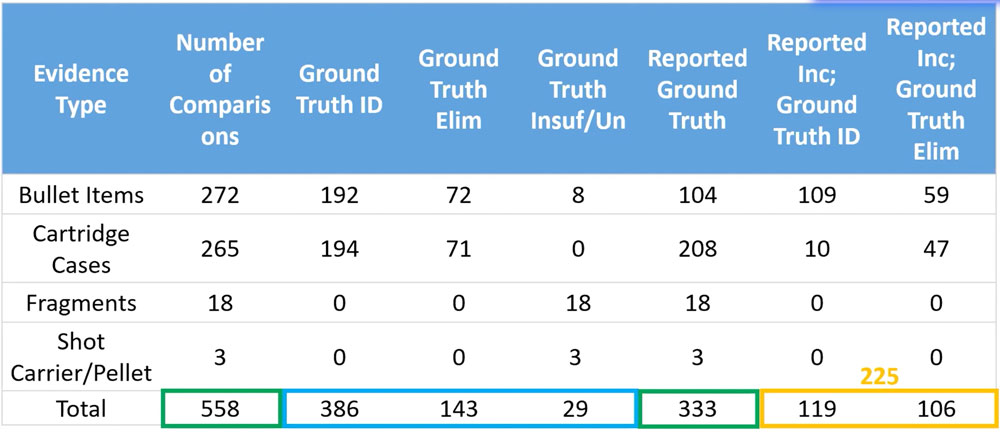
Fired evidence is then marked or documented in a way that relates it back to its corresponding firearm. Cartridge casings and bullet jackets are submitted with ground truths of either identification or elimination. Fragments and bullet cores are expected to be unsuitable or insufficient regardless of which firearm was used to create the evidence.
When a case is ready, it is packaged just like a regular firearms case would be, in an envelope or gun box. Technicians take the evidence to the HPD property room and prepare it with an HPD evidence bar code. The evidence stays there until HFSC makes a request for analysis, enlisting the help of HPD officers who use their names on the request, thus keeping the test blind. When the evidence arrives at HFSC for processing, it is assigned as usual by managers and supervisors who themselves do not know which evidence is real casework and which is test material.
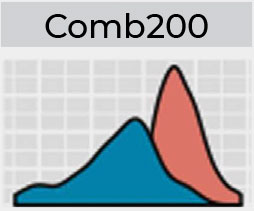
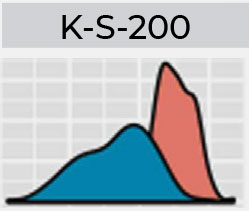
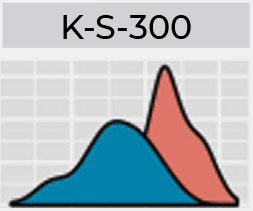
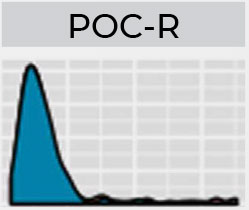
The range of results expected in HSFC’s blind proficiency test program follow the standard operating procedures widely used within the community. A condensed version of the results expected include:


Preliminary results
In the next phase of HSFC’s blind testing program, researchers would like to:

On April 22, the Center for Statistics and Applications in Forensic Evidence (CSAFE) hosted the webinar, Shining a Light on Black Box Studies. It was presented by Dr. Kori Khan, an assistant professor in the department of statistics at Iowa State University, and Dr. Alicia Carriquiry,
CSAFE director and Distinguished Professor and President’s Chair in Statistics at Iowa State.
In the webinar, Khan and Carriquiry used two case studies—the Ames II ballistics study and a palmar prints study by Heidi Eldridge, Marco De Donno, and Christophe Champod (referred to in the webinar as the EDC study)—to illustrate the common problems of examiner representation and high levels of non-response (also called missingness) in Black Box studies, as well as recommendations for addressing these issues in the future.
If you did not attend the webinar live, the recording is available at https://forensicstats.org/blog/portfolio/shining-a-light-on-black-box-studies/
To start to understand Black Box studies, we must first establish foundational validity. The 2016 PCAST report brought Black Box studies into focus and defined them to be a thing of interest. The report detailed that in order for these feature comparison types of disciplines, we need to establish foundational validity, which means that empirical studies must show that, with known probability:
The PCAST report proposed that the only way to establish foundational validity for feature comparison methods that rely on some amount of objective determination is through multiple, independent Black Box studies. In these studies, the examiner is supposed to be considered a “Black Box,” meaning there is some amount of subjective determination.
Method: Examiners are given test sets and samples and asked to render opinions about what their conclusion would have been if this was actual casework. Examiners are not asked about how they arrive at these conclusions. Data is collected and analyzed to establish accuracy. In a later phase, participants are given more data and their responses are again collected and then measured for repeatability and reproducibility.
Goal: The goal with Black Box studies is to analyze how well the examiners perform in providing accurate results. Therefore, in these studies, it is essential that ground truth be known with certainty.
The four common types of measures are False Positive Error Rate (FPR), False Negative Error Rate (FNR), Sensitivity, and Specificity. Inconclusives are generally excluded from Black Box studies as neither an incorrect identification or incorrect exclusions, so inconclusive decisions are not treated as errors.

Representative Samples of Examiners
In order for results to reflect real-world scenarios, we need to ensure that the Black Box volunteer participants are representative of the population of interest. In an ideal scenario, volunteers are pulled from a list of persons within the population of interest, though this is not always possible.
All Black Box studies rely on volunteer participation, which can lead to self-selection bias, meaning those who volunteer are different from those who don’t. For example, perhaps those who volunteer are less busy than those who don’t volunteer. Therefore, it’s important that Black Box studies have inclusion criteria to help make the volunteer set as representative of the population of interest as possible.
In the Ames II case study, volunteers were solicited through the FBI and the Association of Firearm and Toolmarks (AFTE) contact list. Participants were limited by the following criteria:

Problems with this set:

Overall, this is strong evidence in this study that the volunteer set does not match or represent the population of interest, which can negatively influence the accuracy of Black Box study results.
Handling Missing Data
Statistical literature has many rules of thumb stating that it is okay to carry out statistical analyses on the observed data if the missing data accounts for between 5–20% and the missingness is “ignorable”. If missingness is non-ignorable, any amount of missingness can bias estimates. Across most Black Box studies, missing data is between 30–40%. We can adjust for some non-response, but first we must know whether it’s ignorable or non-ignorable.
To make this determination, the following data at a minimum must be known:
Most Black Box studies do not release this information or the raw data. For example:

However, study made much of the necessary data known, allowing researchers to study missingness empirically. If there is a characteristic of examiners that is associated with higher error rates, and if that characteristic is also associated with higher levels of missingness, we have evidence that the missingness is non-ignorable and can come up with ways to address it.
In this example, of the 226 examiners who returned some test sets in the studies, 197 of those also had demographic information. Of those 197, 53 failed to render a decision for over half of the 75 tests presented to them. The EDC study noted that examiners who worked for non-U.S. entities committed 50% of the false positives made in the study, but only accounted for less than 20% of the examiners. Researchers wanted to discover whether examiners who worked for non-U.S. entities had higher rates of missingness. After analyzing the data, researchers found that instead of the 19% of respondents that worked for non-U.S. entities that were expected to have a missingness of over half, the observed amount was 28% of respondents.
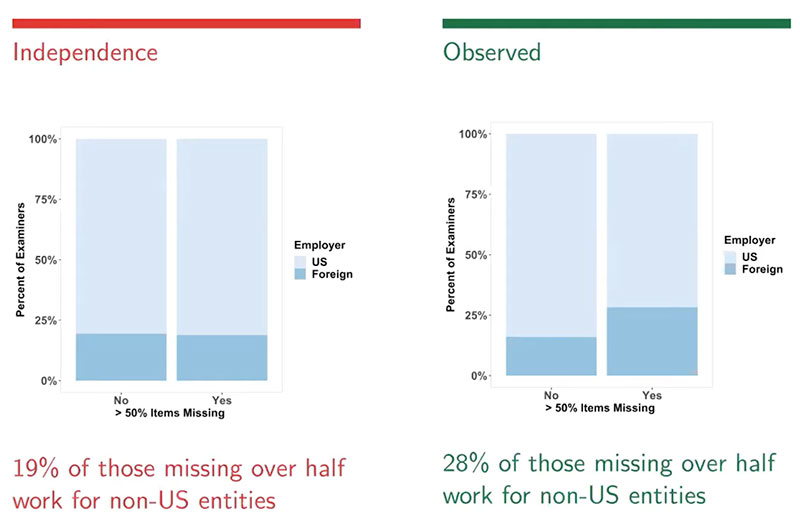
Researchers then conducted a hypothesis test to see if there was an association between working for a non-U.S. entity and missingness by taking a random sample size, calculating the proportion of foreign workers in the sample, repeating many times, and comparing the observed value of 28% to the calculated ones.
Using this method, researchers found that the observed result (28%) would occur only 4% of the time, if there was no relationship between missingness and working for a non-U.S. entity, meaning that there is strong evidence that working for a non-U.S. entity is associated with higher missingness.
Researchers repeated the process to test whether missingness is higher among examiners who did not work for an accredited lab and had similar findings:
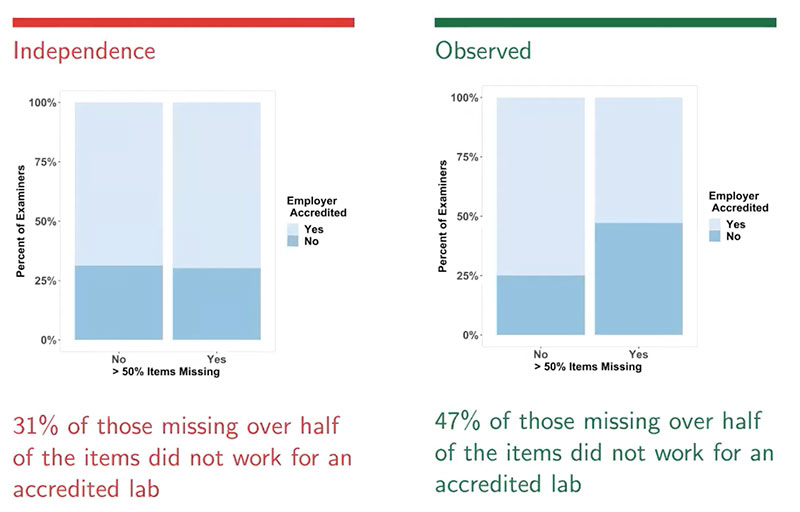
In this case, the hypothesis showed that his result (47% missingness) would only be expected about 0.29% of the time. Therefore, there is strong evidence that working for an unaccredited lab is associated with a higher missingness.
The two issues discussed in this webinar—lack of a representative sample of participants and non-ignorable non-response—can be addressed in the short term with minor funding and cooperation among researchers.
Representation
Missingness